 Поделиться
Поделиться
Как большие данные завоевывают огромные рынки
Данные играют все большую роль в бизнесе. Однако очень важно не собирать избыточную информацию и максимально использовать то, что есть. При помощи искусственного интеллекта, машинного обучения и других технологий можно получить от больших данных очень ощутимую выгоду, считают участники секции «BI и большие данные» организованного CNews Conferences и CNews Analytics очередного CNews Forum 2018.
Отношение к данным зачастую определяет успех бизнеса, а готовность к внедрению новых технологий становится важнейшим фактором победы над конкурентами. Как собирать данные и как их анализировать? Об этом говорили участники секции «BI и большие данные» на CNews Forum 2018.
Открыта она была докладом о том, как прийти к стратегии управления корпоративными данными Data Governance. Модератор секции, ведущий архитектор по данным банка ВТБ Сергей Федечкин, рассказал о том, какой должна быть организационная структура при использовании такого подхода, а также дал несколько советов компаниям. По его мнению, все организационные уровни Data Governance и любых инициатив в области качества и защиты данных должны быть сосредоточены на действительно критически важных для организации сведениях.
Корпоративная функция управления данными
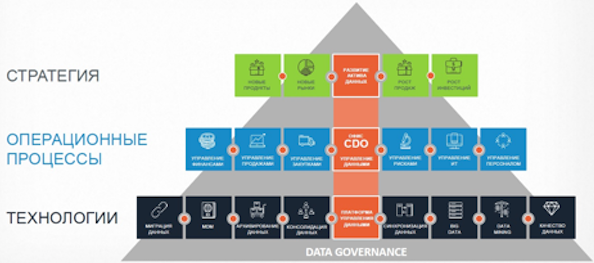
Источник: ВТБ, 2018
«Ключевые рекомендации, которые помогут CDO перейти к целостной модели Data Governance, такие: определить инициативы развития и монетизации актива данных, создать совместные команды из бизнеса и ИТ для реализации инициатив, разработать сначала политики Data Governance для создания и изменения данных, а потом — комплексную программу проектов, — советует Сергей Федечкин. — Пятый шаг — внедрение политики Data Governance для повышения управляемости системами, создающими данные и установление ответственности за их качество и полноту».
Не экономить на технологиях
Актуальность работы с данными для современной экономики — в названиях компаний-докладчиков. Секцию продолжил представитель IBM, что позволило всем следующим спикерам шутить о том, как непросто выступать, когда на разогреве у тебя такой гигант. Эта часть секции скорее практическая: на примере собственной разработки IBM PowerAI, компания рассказала о современных тенденциях рынка решений для управления данными. В том числе, с использованием искусственного интеллекта (ИИ). Тем более, что мировой рынок ИИ в ближайшие 12 лет будет расти невиданными темпами.
В качестве примера он привел внедрение решения по контролю за работой солнечных батарей. Специальная система анализирует их поведение, сведения обрабатываются и быстро передаются оператору, который видит, что что-то вышло из строя и необходимо провести починку. «По большому счету, сегодня все чаще те работы, которые раньше выполнял человек, выполняет машина, – говорит руководитель направления по продажам серверных решений IBM в России и СНГ Константин Мозговой. – Эта машина уже не просто производит вычисления, но и анализирует данные. И это один из основных трендов рынка».






Представитель IBM настоятельно советовал бизнесу не экономить на технологиях. Дешевая разработка — это почти всегда дорогое тиражирование и использование. Тренд сегодняшнего дня — относительно высокие затраты на разработку при очень дешевой эксплуатации.
Технологии и люди
«Данных стало так много, что справиться с таким объемом уже практически невозможно», – такого мнения придерживается исполнительный директор компании Naumen Игорь Кириченко. Он предлагает расширить использование роботов для обработки и анализа данных. Впрочем, аналитика пока остается вне поля зрения многих руководителей компаний, у них проблемы серьезнее: низкая средняя рентабельность по России (5,3%), в три раза меньшая эффективность в сравнении с конкурентами из США и Европы, в два раза меньшая производительность труда.
По мнению спикера, именно использование искусственного интеллекта при работе с большими данными могло бы стать источником развития компании. Ведь современная компания — это цифровой персонал, диалоговые роботы, дополненный интеллект, рекомендательные системы, предсказательные модели и хранители знаний. «Опрошенные нами пользователи считают, что с роботом говорить удобнее, — приводит пример Игорь Кириченко. — Потому что если вам положена скидка, то оператор-робот ее обязательно предложит. А если оператор – человек, то все может зависеть от того, с какой ноги он сегодня встал».
Стоит ли брать на работу роботов?

Источник: Naumen, 2018
Спикер рассказал о новой разработке Naumen – интеллектуальной платформе для создания голосовых и текстовых роботов Erudite. Благодаря таким решениям пользователь больше никогда не будет «висеть» на линии, с чат-ботом смогут поговорить 90% клиентов вне зависимости от возраста и уровня подготовки, а эффективность в сравнении с тем же IVR вырастет в 50 раз. Еще одни бонус — финансовый: оптимизация затрат на сервисные процессы и персонал после роботизации контакт-центра может достигать 40%.
О том, какие решения будут популярны завтра, предложил поговорить руководитель департамента поддержки информационных технологий «Почты России» Сергей Синегубкин. Он рассказал о концепции хьюманизации данных. «К данным можно относиться как к популяции неких существ, например, людей, – пояснил спикер. – В этой концепции несколько ключевых аспектов. Первый — обычная теория эволюция: слабые и ненужные данные должны умирать. Второй — общение: если к данным кто-то обращается, то их ценность увеличивается. Третий — данные могут порождать себе подобных, то есть какие-то новые объекты. Кроме того, данные работают, получают за это вознаграждение, могут умирать, оставаясь в памяти других систем».
Что мешает цифровизации
С докладом о моделях цифровой интеграции выступил Вячеслав Солопов, директор по консалтингу «Консист Бизнес Групп». По его словам, цифровой аналог реальной действительности пока не создан, но попытки предпринимаются, сама цифровизация немного хаотична из-за большого количества новых цифровых процессов и активов, но большие данные постепенно становятся элементами системы цифрового управления. Развитию мешают изоляция данных, разрозненный инструментарий и сложность внедрения большинства моделей.







«Когда мы говорим про «цифру», то должны понимать, что придется склеивать совершенно разные процессы, автоматизированные совершенно разными системами. И во всей этой модели не совпадает не технология, а сама модель данных, — говорит Вячеслав Солопов. — Самой проблемной является шлюзовая сторона, которой предстоит обеспечить интеграцию разрозненных данных».
В качестве примера он привел крупный холдинг, имеющий производственные активы во всем мире. Для того чтобы связать их в единый цифровой процесс, существует три подхода. Первый – создать комплексную информационную систему и объединить в ней все процессы. Второй —наладить обмен данными между разными системами. Третий — внедрить решение, которое позволит просто забирать нужные данные для аналитического контура, а потом их возвращать.
Направление развития платформ данных
Источник: X5 Retail Group, 2018
Как превращать данные в конкретные знания, рассказал участникам секции Эдуард Федечкин, ведущий эксперт по системам бизнес-аналитики «Терн». Самый верный путь — многоаспектная аналитика, которая должна включать в себя все сферы, с которыми соприкасается компания: от клиентской базы и производства до логистики и оценки рисков. Это даст бизнесу финансовую эффективность, предсказуемость и безопасность.
«Эффективнее всего сначала анализировать внутренние источники данных, после чего совместить эти результаты с внешними источниками, такими как соцсети. Это позволяет видеть своего клиента как изнутри, так и во всем пространстве, где он успел наследить», — советует Эдуард Федечкин. С помощью специальных ИТ-средств эти данные очищаются и упаковываются в «витрины». К этому «аналитическому сердцу» прикручивается модуль бюджетирования и планирования, а затем и средства семантического моделирования. После этого строится семантический слой, чтобы руководители компаний могли получать данные в понятном виде.
Лишние данные — лишние траты
Большая компания, у которой нет заводов, производства и торговых сетей. Может ли она стоить миллиарды долларов? Может, считают в компании Avito. «Вам не нужны большие данные. Вам нужны алгоритмы машинного обучения, вам нужен искусственный интеллект, но при этом большая часть времени почему-то уходит на инфраструктурную подготовку», — говорит глава отдела обработки баз данных Avito Николай Голов. По его мнению, менять будущее компании можно не столько с помощью огромных хранилищ, сколько посредством цифровой площадки, на которой можно проводить сотни экспериментов. Такая площадка управляется бизнес-аналитиками и аналитиками данных (data scientist), которые и разрабатывают новые сервисы.
Большие данные — это технологии хранения и обработки структурированных и неструктурированных данных, управление их качеством и предоставление их потребителям, а анализ данных (data scientist) — это распознавание видео, текстов и речи, построение рекомендательных моделей, сегментация и кластеризация. В X5 Retail Group подчеркивают, что это различие важно понимать. «При этом, с точки зрения организации, бизнесу не всегда нужен data scientist», — говорит Андрей Молчанский, директор департамента разработки и сопровождения продуктов больших данных X5 Retail Group. В качестве примера он привел Facebook. Когда-то компания пошла в сторону демократизации данных и предоставила доступ к ним все сотрудникам. Стажер Facebook в свободное от работы время разработал карту взаимоотношений людей между собой. Она была простая, но понятная. Так появился блок «Возможно, вы знакомы».
По словам Льва Рагулина, начальника управления систем отчетности и бизнес-анализа X5 Retail Group, отношение бизнеса к большим данным неоднозначно. «Сейчас многие озера данных заболачиваются. Одни считают, что данные — это ценность, а другие — что их невозможно собирать бесконечно. Универсального рецепта не существует, — отмечает Лев Рагулин. — Но когда вы наполняете свое озеро данных, нужно руководствоваться несколькими принципами. Например, данные должны быть релевантны бизнес-процессам, бизнес-сущностям, чтобы не собирать лишнее, иначе стоимость инфраструктуры может быть неимоверной».
Рост объемов данных вынуждает компании менять свои подходы. Ключевые тренды на этом рынке – симбиоз хранилищ и озер данных, аналитика в режиме реального времени, слияние с интернетом вещей и использование больших данных маленькими компаниями с помощью облаков.
Как использовать данные для роста бизнеса
Последние доклады секции были посвящены конкретным кейсам. Компания «ЛокоТех» появилась на свет после реорганизации РЖД, ее задача — ремонтные работы, обслуживание и модернизация оборудования. «Мы должны знать о локомотиве все: как он спроектирован, как изготовлен, как его эксплуатировали и как обслуживали. И эта информация должна храниться на протяжении всего жизненного цикла локомотива, – рассказывает Дмитрий Сергиенко, управляющий директор по развитию цифровых технологий «ЛокоТех». – А локомотив — достаточно сложная конструкция, он состоит из 30 тысяч элементов и деталей. И практически с момента его выпуска начинается сбор и обработка информации из различных систем: РЖД, бортовых и так далее. Все эти данные отправляются в хранилище вместе со сведениями о том, какие работы выполнялись, какие дефекты обнаруживались».
Компания приступила к созданию платформы, которая будет выстроена на микросервисной инфраструктуре с последующей интеграцией всех существующих в компании платформ (ERP, BI, PLM, MDMи других) в единое целое. Она станет основой для совместной работы всех заинтересованных сторон и обеспечит рост бизнеса предприятия, уверены в «ЛокоТех».
Руководитель отдела разработки CarPrice Юрий Буйлов рассказал о платформе, которая позволяет упростить процесс продажи и покупки автомобиля. «Наша компания работает фактически на стыке онлайн- и офлайн-процессов. Мы используем данные для роста бизнеса и повышения качества предоставляемых услуг. Нами создана внутренняя система, которая позволяет качественно сэкономить время: за 2-3 часа вы можете продать автомобиль», — говорит спикер.
Кроме того, платформа позволяет получать данные о загруженности центров осмотра: пользователям доступны управление записью, подбор удобного времени и возможность назначить выездной осмотр. Насыщенные данные о сделке (демография, класс автомобиля, подбор инспектора) поднимают конверсию ресурса на 2-5%, а маржинальность — на 10-15%. Компания активно использует технологии машинного обучения. Основываясь на сведениях об автомобиле, дилере и самом аукционе, нейронной сетью рассчитываются и повышаются ставки. По итогам работы рекомендательной системы средняя стоимость авто при продаже выросла на 2%.

О том, как движется процесс цифровой трансформации и какую роль в этом играют большие данные, рассказал CNews Вячеслав Солопов, директор по консалтингу «Консист Бизнес Групп».
CNews: Как соотносятся цифровизация и управление большими данными?
Вячеслав Солопов: Цифровые данные сегодня появляются вне зависимости от наличия или отсутствия цифровых процессов, потому что часть из них так или иначе переходит в ИТ. После этого у нас появляются данные. Гаджетизация, большое количество социальных сетей, процессы автоматизации бизнес-процессов и сообществ — все это генерируют большие данные, но при этом, они появляются и сами по себе.
 Короткая ссылка
Короткая ссылка









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}