Как начать работать с большими данными без капитальных затрат


В преимуществах облаков и выгодах, которые несет с собой их использование, не сомневается уже никто. По сути, облака не нужны только тогда, когда заказчик может точно рассчитать нагрузку на инфраструктуру и объем хранимых данных на пять лет вперед и уверен, что эти показатели не изменятся. На практике это фактически невозможно. А значит, компании необходимо приобрести мощное и дорогое оборудование, но уровень его загрузки не будет превышать 5%. Или, наоборот, сэкономить на инфраструктуре, и в момент стремительного роста бизнеса оказаться в ситуации, когда она просто не выдержит.
При той скорости, с которой меняются условия ведения бизнеса, развитие ИТ-систем все больше становится похожим на бесконечный внутренний стартап: совершенно непонятно, что будет не просто через два-три года, а даже через год. И чем активнее развивается ИТ-система — тем выше уровень неопределенности, а значит, и выше риски. Дополнительные сложности создает дефицит квалифицированных ИТ-специалистов.
При этом гарантировать, что подобные инвестиции будут оправданы, не рискнет никто.
Допустим, компания решила объединить данные из разрозненных ИТ-систем с тем, чтобы наконец-то увидеть цельную картину того, что происходит в бизнесе. Построение такой платформы данных — сложная и затратная задача.
Надо закупить достаточно дорогое оборудование, что в условиях глобального дефицита полупроводников займет от трех месяцев до года. Потребуется найти редких специалистов, квалификации которых будет достаточно для развертывания и обслуживания сложных систем корпоративных хранилищ. Такие эксперты зачастую заняты на крупных проектах, поэтому срок поиска релевантного персонала может растянуться до бесконечности.
На помощь приходят облака. Конечно, для создания современной платформы данных в этом случае тоже потребуются профессионалы — они должны будут разработать структуру хранилища и настроить потоки данных из источников.
Однако, используя современную облачную платформу, можно пропустить длинный и сложный этап закупки оборудования. А значит — быстрее добиться поставленной цели, использовать ровно столько ресурсов, сколько необходимо в данный момент, минимизировать риски и сократить издержки на эксплуатацию: современные облачные платформы предлагают готовые сервисы «из коробки», ответственность за работу которых несет провайдер.
Это могут быть простые сервисы — такие, как сервис оркестрации контейнеров, уже готовый к работе в геораспределенном режиме — или сервис реляционной СУБД, также имеющий возможность переключения в другой ЦОД. Или более сложные — например, сервисы для обработки больших данных, настройка и эксплуатация которых требует наиболее редких и дорогих специалистов на рынке.
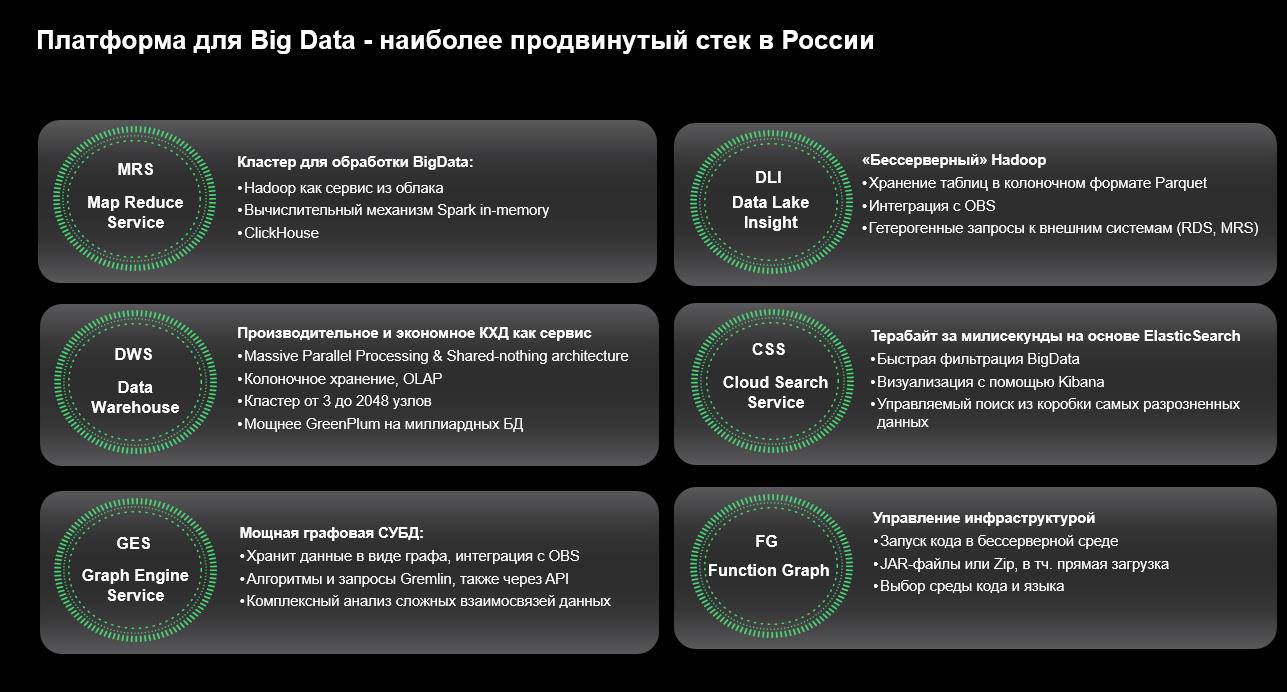
Так, в облаке SberСloud.Advanced, реализованном в партнерстве с Huawei, представлен целый ряд готовых решений, позволяющих начать использование больших данных без капитальных затрат.
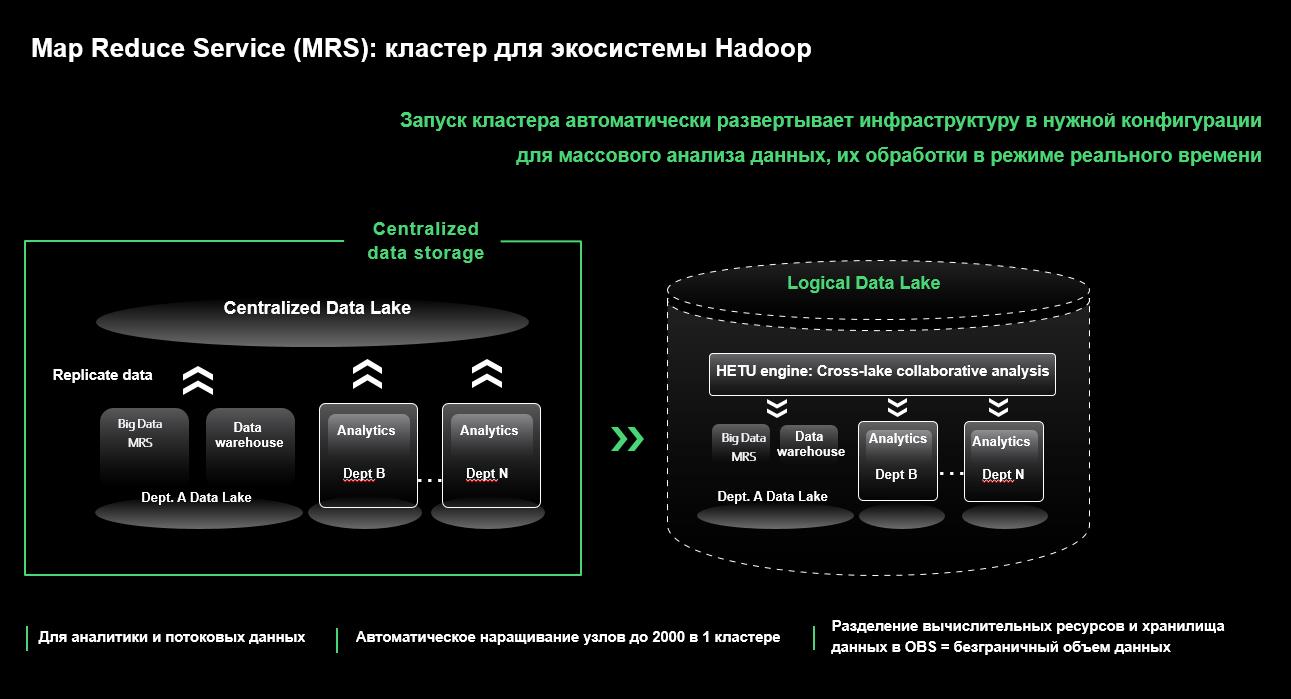
Map-Reduce Service — готовый кластер для экосистемы Hadoop. Его можно настроить для различных сценариев (аналитические запросы, анализ потоков данных в реальном времени). Он умеет автоматически наращивать число узлов кластера при недостатке ресурсов и в целом может содержать до 2000 узлов в одном кластере. Сервис интегрирован с объектным хранилищем в облаке и может эксплуатироваться в режиме разделения вычислительных ресурсов и хранилища (compute-storage separation), в котором данные лежат не на локальных дисках в виртуальных машинах, а в объектном хранилище, а значит, размер данных потенциально не ограничен.
- Когда полноценный кластер Hadoop избыточен, используйте DLI как сервис из облака
- SQL запрос - сбор данных из различных внешних систем без копирования данных
- Простейшая платформа данных на базе одного сервиса DLI
В случае, если полноценный кластер Hadoop кажется избыточным или объем данных не слишком велик для того, чтобы держать его в готовности все время, облако предлагает более экономичный вариант в виде сервиса Data Lake Insights. Это, по сути, бессерверный Hadoop, в котором ресурсы выделяются по требованию. Например, если задача запускается раз в сутки и работает час, выгоднее применить DLI, где будет временно выделена нужная мощность, а после выполнения задачи инфраструктура освободится до следующего запуска. Кроме того, DLI уже содержит возможность подключения к внешним источникам любых данных: начиная от файлов и заканчивая реляционными СУБД. Это позволяет в рамках одного SQL-запроса собрать данные из различных внешних систем, не копируя их куда-либо. А значит, построить простейшую платформу данных, используя всего лишь один сервис Data Lake Insights.
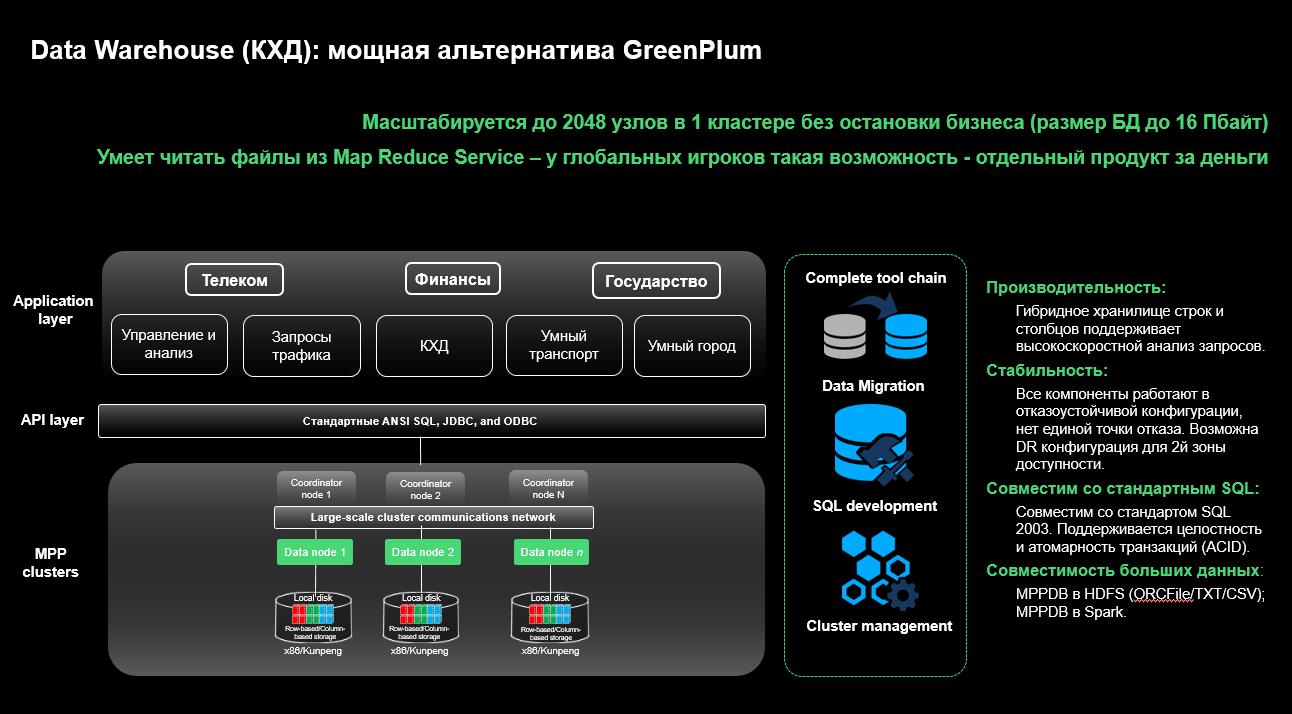
Еще один сервис — Data Warehouse Service — предназначен для построения классических корпоративных хранилищ данных. В его основе лежит реляционная СУБД PostgreSQL, работу с которой поддерживают абсолютно все существующие инструменты аналитики. Сервис представляет собой массово-параллельную СУБД, в которой отсутствует единая точка отказа. СУБД оптимизирована для OLAP-запросов и не требует оптимизации при построении особенно сложных аналитических запросов. Как и Map-Reduce Service, Data Warehouse Service может масштабироваться до 2048 узлов в одном кластере, при этом размер базы данных может достигать 16 петабайт. Он интегрирован с другими сервисами, в частности, может напрямую читать файлы из объектного хранилища как таблицы. Но что самое интересное, он точно так же умеет читать файлы из Map-Reduce Service. У глобальных игроков на рынке СУБД такие возможности предоставляются как отдельный продукт за отдельные деньги.
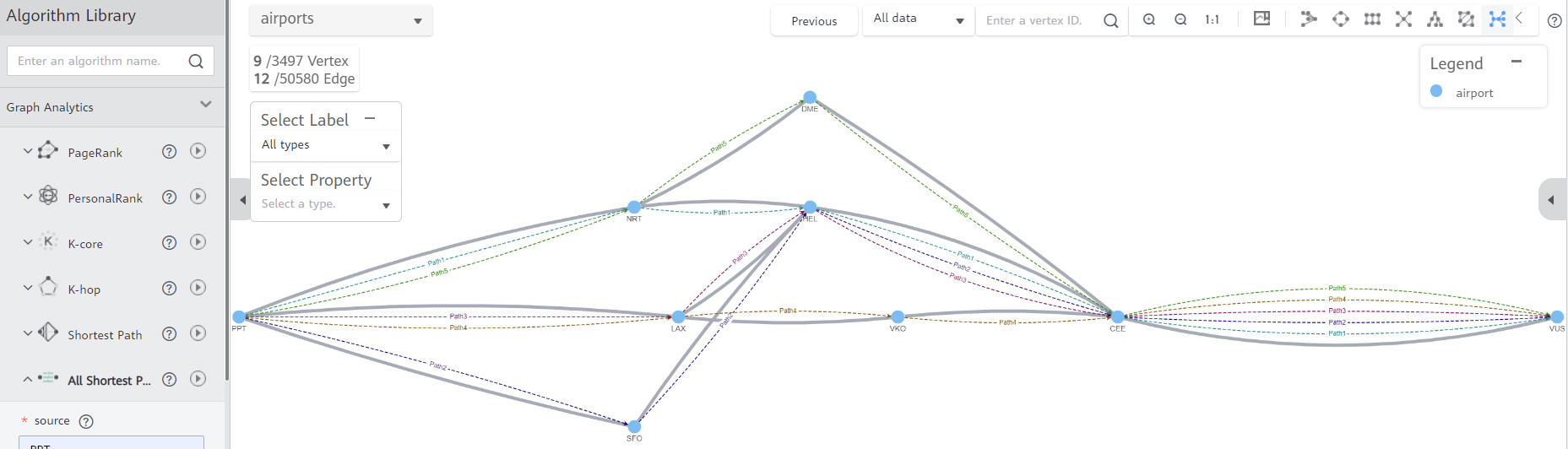
Стоит упомянуть еще Graph Engine Service — специальную СУБД для хранения и обработки информации в виде графов. Применение такого сервиса всегда будет нетривиальным. Интернет-компании смогут быстро и эффективно обогатить данные сложных взаимосвязей социальных сетей, финансовые организации — предотвратить мошенническое поведение или настроить рекомендательную систему кредитного скоринга, логистические и транспортные компании — оптимизировать доставки за счет поиска кратчайшего пути, государственные органы — эффективно управлять транспортными сетями и городским хозяйством, а крупный бизнес — повысить качество менеджмента ИТ-инфраструктуры.
И, наконец, еще один сервис, который необходим для построения платформы данных и связывает все упомянутые выше сервисы воедино. Это сервис пакетного обмена между различными источниками Cloud Data Migration. Он поддерживает пакетную передачу данных любого объема между практически любыми СУБД: MySQL, MSSQL, Oracle, PostgreSQL, SAP и т. д. Cloud Data Migration может быть настроен на работу по расписанию и выполнять простейшие преобразования данных в процессе переноса. Фактически это встроенное ETL-средство, без которого не обходится построение любой сложной системы обработки данных.
Спрос на платформы растет, равно как и растет спрос на сервисы работы с большими данными — это тенденция сегодняшнего времени. Использовать их в облаке — гораздо проще. В случае, если сценарий публичного облака не релевантен заказчику, развивать возможности частного облака можно на базе решения Huawei Cloud Stack, имеющего обширный пул сервисов, сравнимый с публичным облаком.
Сегодня заказчики, находясь на различных стадиях цифровой трансформации, осознанно приходят к необходимости реализации data-driven подхода внутри компании, для максимального использования накопленной информации в целях развития бизнеса, оптимизации самих процессов кристаллизации ценностей имеющихся данных. Зачастую ищут на рынке подобные решения среди готовых продуктов вендоров, понимая при этом сложность внедрения и поддержки столь комплексного решения. В этой связи растет технологическая и консалтинговая нагрузка на ИТ-команды (не важно, внутренние или внешние), готовые пройти с заказчиком этот нелегкий путь. Конечно, компании гораздо легче встают на путь платформизации процессов управления и обработки данных уже имея в своем базисе Cloud-ready конфигурацию инфраструктуры. Но тем не менее, облако способно решить задачи бизнеса при любом текущем раскладе.