


Что такое большие данные c позиции современных корпоративных систем и информационных технологий? Это серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объемов, значительного многообразия и непрерывного прироста. Целью обработки больших данных является получение информации, которой уже сможет оперировать человек.
В качестве определяющих характеристик для больших данных отмечают «три V»: объем (англ. volume – величина физического объема), скорость (англ. velocity – скорость прироста и необходимость высокоскоростной обработки и получения результатов), многообразие (англ. variety – разнообразие данных и возможность их одновременной обработки).
Большие данные стали значительно актуальнее, чем привычки думать, но терминология в России еще не прижилась. Например, в СМИ с большими данными связаны оценка интересов пользователей, отслеживание социальной активности, количество перепостов, автоматическая подготовка дайджестов и даже новостей. В медицине большие данные накапливаются за счет использования электронных медицинских карт, нательных датчиков, данных со стационарных медицинских приборов. При анализе огромных объемов информации становится возможным прогнозирование эпидемий. В науке такие подходы актуальны в метрологии, геологии, метеорологии, астрономии. Спортивный менеджмент завязан на больших данных; за счет анализа больших объемов информации осуществляется прогноз продажи билетов, расчет букмекерских коэффициентов.
Большие данные в корпоративных системах
Но это в повседневной жизни. Отдельно стоит разобраться в том, что происходит на уровне корпоративных систем, в частности систем управления корпоративным контентом – ECM. Динамика прироста данных выше, чем динамика прироста пользователей системы. Сотрудники компании активнее используют ECM-систему, инициируется больше бизнес-процессов, как связанных с классическим делопроизводством (входящие, исходящие, организационно-распорядительные документы), так и лежащих за его пределами: работа с договорами, счетами, финансовым архивом, межкорпоративное взаимодействие. Как раз неклассические задачи и придали большой рывок.
Число пользователей системы
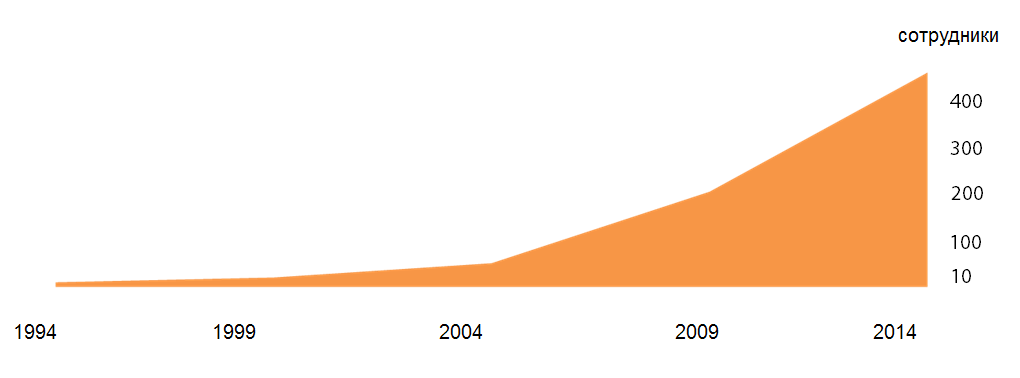
Источник: Directum, 2014
Удельный объем данных на одного сотрудника все возрастает, как и их разнообразие. При этом рано или поздно должен наступить момент, когда люди перестанут справляться с информацией, потонут в ней. Чтобы разобраться, есть ли тут большие данные, надо разделить все бизнес-задачи на классические и неклассические. Под первыми подразумевается работа с ОРД, входящими и исходящими документами, несложными бизнес-процессами – с ними проще разобраться. Неклассические – это обработка счетов за оплату, ведение финансового архива, обработка обращений населения, кредитные заявки и прочее – зачастую именно они связаны с взрывным ростом объема данных.
Число накопленных в системе документов
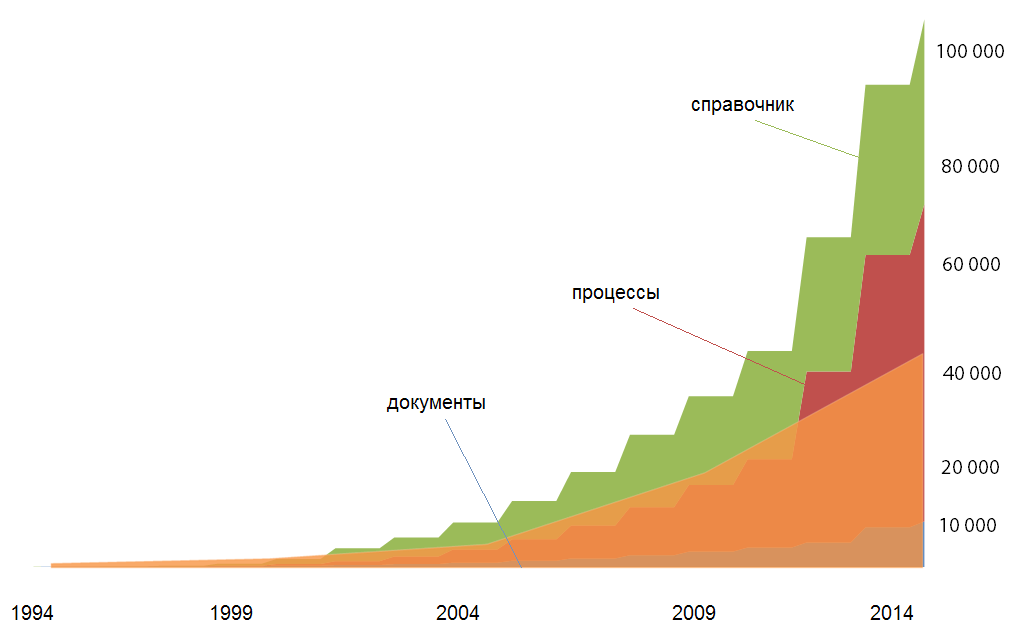
Источник: Directum, 2014
В крупной компании с одновременной работой в ECM-системе 1000 пользователей и динамикой роста подключений до 3000 до конца года даже в рамках решения классических задач за год в системе инициируются миллионы бизнес-процессов, появляются миллионы документов и РКК. Это гигабайты информации.
| День | Месяц | Год | |
|---|---|---|---|
| Пользователи | 1000 | 1200 | 3000 |
| Регистрационно-контрольные карточки (РКК) | 5400 | 130 000 | 3 888 000 |
| Документы | 5500 | 132 000 | 3 960 000 |
| Процессы | 8400 | 202 000 | 6 048 000 |
При таких объемах классических задач документооборота и начинается работа с большими данными. При этом крайне важно обеспечивать масштабируемость, возможность получения статистики и анализа работы в режиме реального времени.
Неклассические задачи и взрывной рост данных
Различные неклассические задачи могут быть в госсекторе, банках, ритейле. Например, в рамках реализации пилотного проекта в одном субъекте РФ по переводу государственных и муниципальных услуг в электронный вид, было замерено, что из регионального органа в федеральный центр поступает 270 тыс. обращений в год. Одновременно внутри региона генерируется 70 тыс. обращений. И это только пилотный проект на первом десятке госуслуг, потом объем может до миллионов обращений. А если взять во внимание все субъекты РФ, то объем увеличится до сотен миллионов обращений в год.
В потенциале МФЦ должен обрабатывать до 50 тыс. документов в день или 12 млн в год. Объем документов составит более 100 гигабайт в день или 25 терабайт в год. Это колоссальное количество передаваемой информации. Все эти данные надо хранить и обрабатывать при новых запросах граждан.
В банки ежедневно может поступать до 10 тыс. обращений с заявками на потребительские кредиты. Только приемом таких заявок в едином центре будут заниматься 200 сотрудников. А после приемки заявки необходимо обработать, провести через кредитный комитет и вынести по ним решения о выдаче кредита. Оптимально, если одна заявка будет обрабатываться не в течение нескольких дней, а за час. Если для автоматизации принятия решения существуют специальные информационные системы, то в области ввода и первоначальной обработки информации ИТ-решения только-только начинают использоваться.
Через крупные торговые сети ежемесячно проходит до 100 тыс. бумажных счетов. Все счета, как правило, обрабатываются в корпоративном центре. Одной из важных задач ритейлеры ставят переход на электронное взаимодействие с контрагентами, потому что уже сейчас текущие объемы данных ставят в тупик бухгалтерию при необходимости быстро сформировать подборку документов для встречной или камеральной проверки. Серьезной проблемой становится также поиск площадей для хранения документов. А с переходом на электронное взаимодействие при интеграции с EDI количество документов вырастет еще больше за счет появления сопроводительной электронной договорной документации.
Большие массивы данных в ECM-системах накапливаются и обрабатываются уже сейчас – это документы, бизнес-процессы, записи справочников, история, права доступа и т.д. Помимо их хранения, необходимо управление, проведение анализа и поиск новых путей повышения производительности работы. Если с отчетностью все более или менее понятно, то поиск гипотез о поведении пользователей, вопросы повышения эффективности бизнес-процессов ставят перед ECM-системами и их потребителями новые задачи. Можно говорить, что ECM-системы переходят из разряда только накапливающих записи (Records System) в разряд систем, способных помочь в анализе (Business Intelligence) и даже вовлечении (Engagement Systems).
Анализ данных и вовлечение сотрудников
Современные корпоративные системы способны предоставить различные механизмы по анализу данных. Развитие интеллекта в стандартном ПО поставлено на поток. Речь идет и об отчетах, и об анализе в режиме реального времени на контрольной панели. Можно оценивать частоту работы с документами в системе для автоматического принятия решений о переносе их в архив, смене прав доступа или даже для формирования подборок подходящих для определенного круга сотрудников документов для текущей работы.
Число обращений к документу, описывающему технологии и процессы
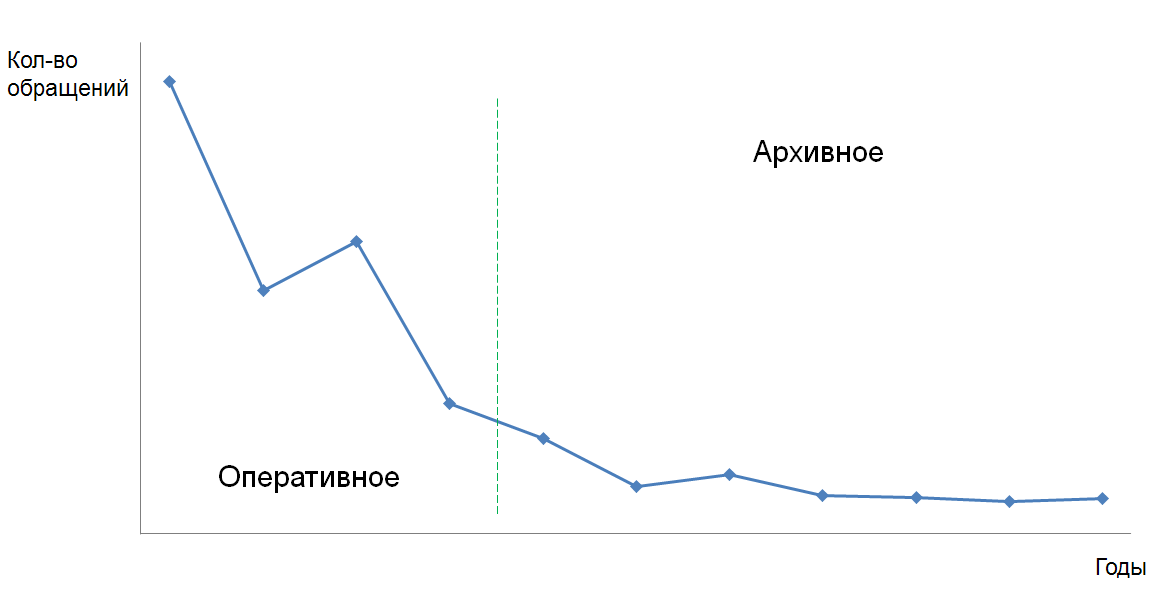
Источник: Directum, 2014
В период появления документа большое количество сотрудников массово его просматривали. С течением времени поток обращений снизился и зафиксировался на уровне только новичков (т.к. базовым технологиям текущие сотрудники уже привыкли следовать). На основе такой статистики система сама может сделать вывод о необходимости переноса документа в архивное хранилище, а также включение его в список обязательных документов для всех новичков.
Существует так называемый профиль загрузки сотрудников. Система сама может оценить профиль загрузки сотрудника, в том числе статистику работы с документами и выполнения заданий, может посылать сигналы о необходимости гармонизации загрузки, перераспределения процессов на коллег.
Статистика о работах и загрузке сотрудника в ECM-системе
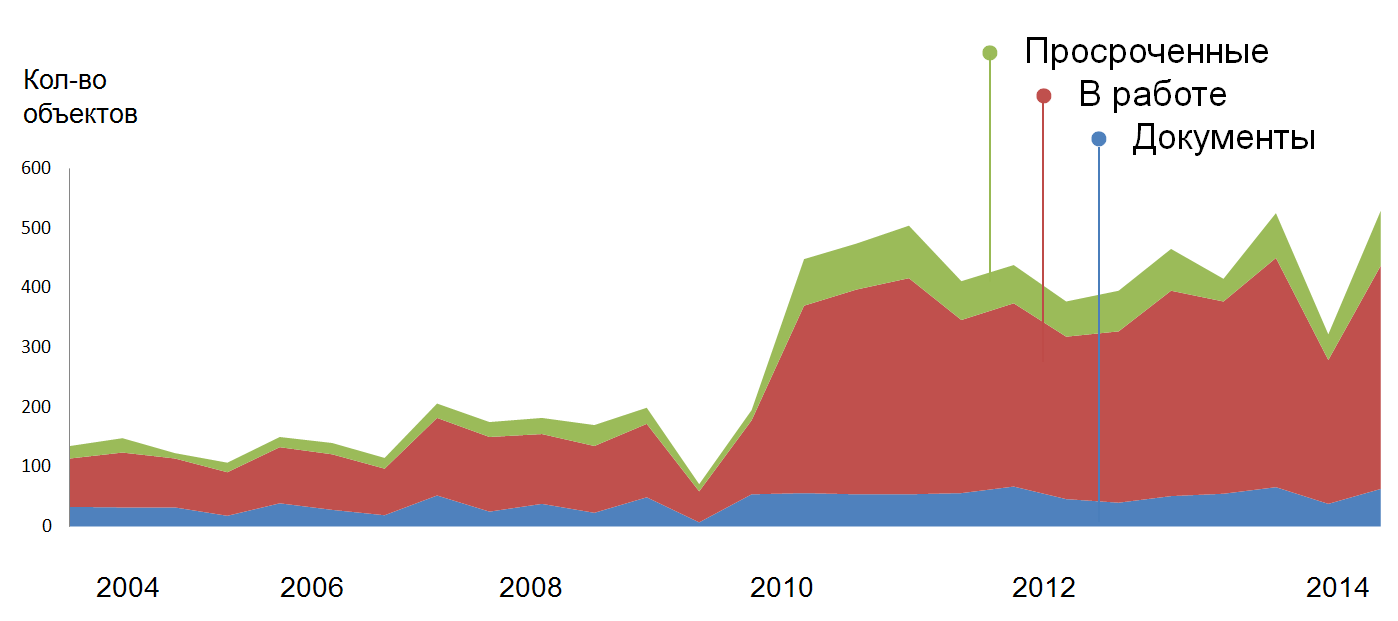
Источник: Directum, 2014
Система может понять, что в 2009 г. сотрудник перешел на руководящую должность, отметив, что его профиль работы сменился, что он стал выполнять больше «быстрых» заданий, вероятно, больше делегировать. Процент просроченных остался неизменным, но с учетом роста количества задач, количество просроченных стало угрожающим. Вероятно, отследив это средствами системы, стоит сигнализировать о факте роста просроченных заданий.
«Цифровой след» сотрудника
Также интересным с позиции больших данных является отслеживание «цифрового следа» сотрудника, оставленного при работе с различными массивами данных, взаимодействии с коллегами, прочей рабочей активности. На основе «цифрового следа» могут выявляться поведенческие гипотезы, которые позволят повысить удобство взаимодействия с системой, окружением (другими системами, коллегами). В результате можно выйти на уровень вовлечения сотрудника к работе в системе (Engagement System) и, тем самым, повысить общую эффективность.
Внедрение в корпоративное окружение элементов игры может стать инструментом анализа поведения пользователей, стимулирования правильного использования функций системы и глубокого их изучения, следования технологиям компании и повышения эффективности. Внедренные элементы подтвердили предположения о том, что новый подход становится стимулом для сотрудников. Также выявился неожиданный факт, что основными участниками становятся не молодые сотрудники, а опытные, в возрасте за 30 лет, а также топ-менеджмент, который нашел в игрофикации новый элемент поиска активных сотрудников и оценки их эффективности.
Процент сотрудников, отметивших конкретные плюсы игрофикации
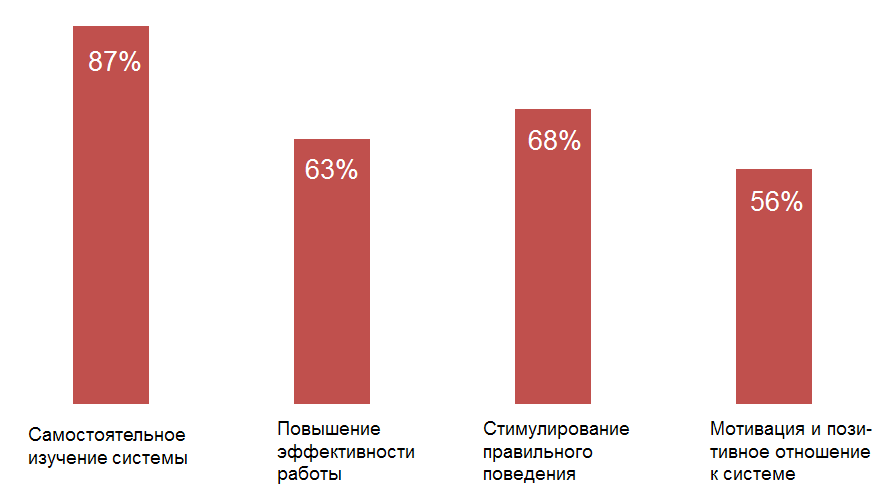
Источник: Directum, 2014
Другим механизмом вовлечения может стать пересмотр принципов работы сотрудников в корпоративных системах – от контента к взаимодействую внутри рабочих групп. Формирование кругов по интересам (отделы, крупные проекты, рабочие группы, профессиональные клубы и гильдии), получение информации от таких социальных групп, формирование профессиональных дайджестов, внутренних чатов – все это инструменты, которые могут помочь в вовлечении сотрудников и повышении эффективности их работы.
Поиски закономерностей внутри работы плотно взаимодействующих групп, быстрая передача им полномочий и информации, закрепление результата, неформальная субординация, принципы хранения и использования данных – все это становится возможным при включении социальных механизмов в корпоративную среду. Если речь идет о крупной компании, имеющей в штате тысячи сотрудников, накопление корпоративной статистики и ее анализ непосредственно связаны с большими данными.
Где проходит граница больших данных в ECM?
Потребности в глубоком анализе слабоструктурированных данных и поиске новых гипотез требуют все большего и большего массива данных, а накапливаются они в ходе работы сотрудников. Современные аппаратные средства помогают обеспечить дешевое хранение. Формируется привычка постоянного накопления корпоративной информации. В том числе за счет этих факторов ECM-системы начинают занимать в компаниях инфраструктурный уровень.
Но надо найти границу возможностей текущих корпоративных средств, преодолеть которую вполне возможно за счет роста разнообразия и объемов данных. Для оценки системы используются три базовых элемента: количество пользователей, разнообразие и объем процессов и история работы в ECM-системе.
Граница больших данных в ECM
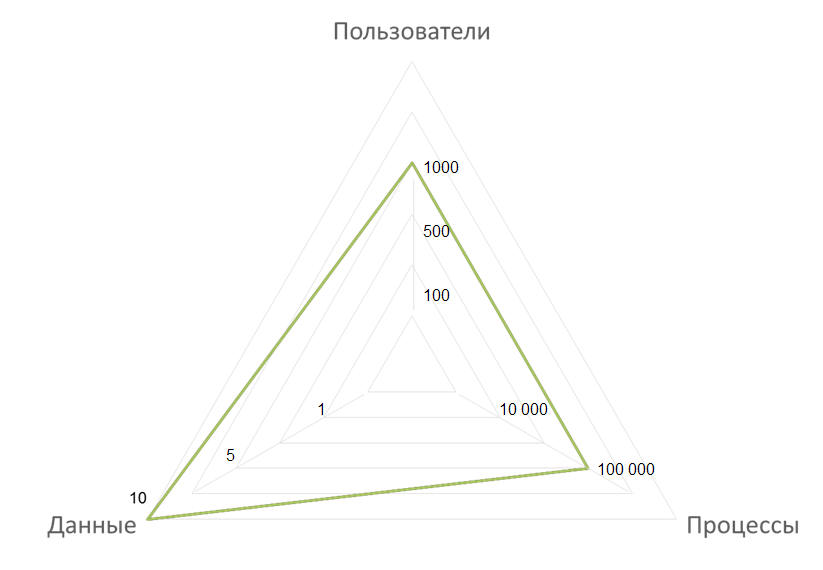
Источник: Directum, 2014
До тех пор, пока компания находится в треугольнике до 1 тыс. пользователей, до 100 тыс. экземпляров запущенных процессов и с историей работы менее 10 лет, данные можно достаточно быстро анализировать средствами текущих корпоративных систем. Но позже придется столкнуться с большими данными, что заставит изменить подходы и средства работы с информацией.
При приближении к границам треугольника желательно задуматься о применение механизмов хранения и обработки больших данных, таких как масштабируемость и отказоустойчивость, возможности применения технологий inMemory, CEP, Data Mining. Необходимо оценивать объемы, разнообразие, скорость прироста и оперативность анализа данных. Если компания ожидает взрывного роста данных, нужно серьезно отнестись к поддержке механизмов их обработки.
 Поделиться
Поделиться




