


Сервисы на основе моделей машинного обучения (ML) широко используют компании большинства отраслей — от ритейла и банкинга до промышленности и добычи полезных ископаемых. Эффект от их использования бывает весьма значителен, но не всегда предсказуем и стабилен. Ниже Александр Борисов, руководитель направления Data Science в компании «Иннодата» разбирает причины этого, а также подходы к решению для внутренних команд, внедряющих и эксплуатирующих ML-сервисы. Причем не с технической стороны (это слишком обширная тема для одной статьи), а со стороны бизнеса и баланса интересов участников таких команд.
Начнем с ключевых ролей в командах внедрения ML-сервисов. Их три. 1. Спонсор — ставит бизнес-цели и выделяет бюджет на их реализацию. Его обычно не интересует, что происходит «под капотом», главное — чтобы ML-сервис выдавал нужный результат, был стабилен и предсказуем как в эксплуатации, так и при развитии. 2. Product Owner — реализует бизнес-задачу в виде ML-сервиса с помощью ИТ-команды, и служит «толмачом» между ней и бизнесом. В зоне ответственности Product Owner'а — эффективность конкретной реализации и декомпозиция бизнес-целей на задачи создания, эксплуатации и развития ML-сервиса. И все это — в рамках выделенного бюджета. 3. Data Science-команда — реализует поставленные задачи, исходя из своего опыта (связанного с машинным обучением, а не с бизнесом), доступных ресурсов и инструментов.

Тут важно, что интересы этих ролей не совпадают — спонсору нужен понятный результат, Product Owner ищет эффективные решения, а DS-команде нужны решаемые задачи и инструменты для их реализации. И самое важное — все оценивают свои действия в разных «системах координат» (деньги и ROI, решения и приоритеты, закрытые задачи и ML-метрики). Есть ли способ объединить все интересы и направить развитие ML-сервиса в верном направлении? Практика показывает, что простого решения нет — нужны как методологические, так и технологические изменения в процессах развития.
Зачем нужен MLOps
Итак, в компании уже есть хранилище данных, и сформирован бизнес-запрос на их использование для достижения измеримой бизнес-цели с помощью ML. Представим, что команда внедрения успешно прошла все этапы до внедрения ML-сервиса в продукционный режим («Прод»). Это можно рассматривать как разовое действие для ИТ: обернули в Docker-контейнер, запустили и забыли — до первого инцидента. Но в случае с ML-сервисом возникает ряд дополнительных требований и ограничений:
- Нужно понимать, как был получен тот результат, который будет выведен в «Прод». Это и история экспериментов (параметров обученных ML-моделей и данных для их обучения), и версии использованных ML-библиотек (окружение), и достигнутые ML-метрики, и возможности для масштабирования. В общем, нужна организация пайплайнов обучения и тестирования ML-моделей и их версионирование.
- Нужно создать механизмы по обработке и получению входных данных для моделей в «Прод» и передаче их результатов потребителям. Это организация пайплайнов эксплуатации (инференса) ML-моделей.
- Нужно реализовать сам вывод в «Прод» и возможности для обновления пайплайнов эксплуатации (зачастую совмещенные с пайплайнами дополнительного обучения). Это организация CI/CD-процессов для ML-сервисов.
- Наконец, нужно настроить мониторинг ML-сервиса в «Прод» — сюда входит как общая доступность и быстродействие сервиса, так и отслеживание ML-метрик инференса при эксплуатации
Все эти задачи объединяются подходом и инструментами MLOps (DevOps для ML-моделей). На первый взгляд, они нужны только Data Science-команде и частично Product Owner'у. Но у MLOps есть и существенные бизнес-эффекты, важные для Спонсора — прежде всего, это кратное снижение Time-to-Market для новых ML-сервисов (недели вместо месяцев), а также существенное снижение расходов на их эксплуатацию. В нашем продукте «Иннодата-MLOps» реализованы все необходимые инструменты для этих задач, позволяющие легко и быстро создавать, выводить в «Прод», обновлять и мониторить все требуемые пайплайны, используя визуальные интерфейсы. При этом сам продукт развертывается в среде Kubernetes, что позволяет реализовать как горизонтальное масштабирование любого числа ML-сервисов (в т.ч. динамическое выделение ресурсов при пиковых нагрузках), так и их изоляцию для исключения взаимного влияния при эксплуатации и обновлениях.
Как управление данными (Data Governance) помогает в развитии ML
Однако бизнес-эффект от ML-сервиса достигается не только (и не столько) с помощью самих ML-моделей, а в первую очередь — за счет данных, которые они используют при эксплуатации. Здесь работает принцип «мусор на входе — мусор на выходе». Например, сбой или неудачное обновление на источнике данных приводит к неверным прогнозам модели, и компания теряет деньги, причем дважды — за счет простоя сервиса и сложного процесса выявления причин сбоев и их устранения. Помимо мониторинга самого ML-сервиса (качество прогнозов, наличие входных данных), в этом случае помогает подход Data Governance и инструменты для его реализации:
- Data Quality — позволяет реализовать автоматические проверки качества входных данных для ML-моделей, причем с использованием удобного визуального интерфейса. При обнаружении отклонений создаются задачи на сотрудников поддержки (дата-стюардов).
- Data Lineage — реализует прослеживание источников данных и их связей на основе метаданных БД, а также их полную визуализацию. Это помогает как в выявлении и устранении причин отклонений, так и в разработке новых ML-моделей. И, конечно, кратно снижает риск дублирования при разработке функционала.
- Бизнес-глоссарий — связывает бизнес-термины («объем продаж в филиале N за месяц») с конкретными БД, таблицами и полями в них (находится в БД Oracle 7 / таблице SalesDB 2 / поле MonthSum4). Функционал позволяет не только разово описать сложившуюся ситуацию, но и отслеживать ее изменения. Таким образом, данные в компании становятся сервисом, доступным широкому кругу сотрудников — как бизнес-аналитикам и Product Owner'ам, так и Data Science-команде. В итоге любая задача, описанная на бизнес-языке (построить модель прогнозирования продаж в филиале N), становится доступной для быстрой реализации,
В этой области мы объединили усилия с ведущим поставщиком решений для хранения данных на российском рынке — компанией Arenadata, которая выпускает отечественный продукт Arenadata Catalog (ADC). Игорь Моисеев, директор по развитию продукта ADC, считает новый этап сотрудничества важным не только для развития партнерских отношений, но и для рынка в целом: «Разработка и внедрение интегрированных отечественных продуктов, объединяющих инструменты продвинутой аналитики на основе машинного обучения и каталогизации данных Arenadata Catalog, позволяет существенно повысить производительность DataScience-команд и, как следствие, — эффективность бизнеса наших клиентов за счет сокращения временных и финансовых ресурсов на внедрение передовых импортонезависимых решений и увеличения окупаемости инвестиций в них».
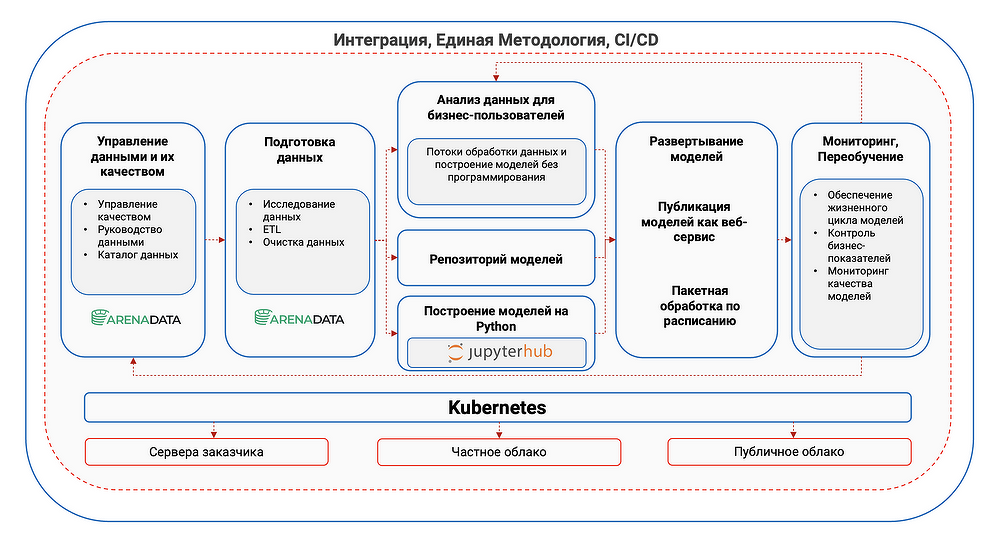
Также в рамках внедрений мы разрабатываем служебные ML-модели для контроля Data Drift — так называемого сдвига в данных, когда при эксплуатации ML-моделей на вход начинают поступать данные, существенно отличающиеся по своему характеру от тех, на которых обучалась модель. Например, такое массово происходило в пандемию Covid-19 с моделями прогнозирования спроса, когда сама структура потребления и поведение потребителей продуктов резко поменялись. Качество прогнозов модели снижается, и в этом случае нужно дообучить либо заменить используемую модель. Если мы сразу установили причину снижения качества прогнозов, то такие изменения проходят максимально оперативно — иногда в режиме, близком к онлайн.
D/MLOps – эффекты от объединения подходов. Как мы делаем ML-сервис понятным для бизнеса
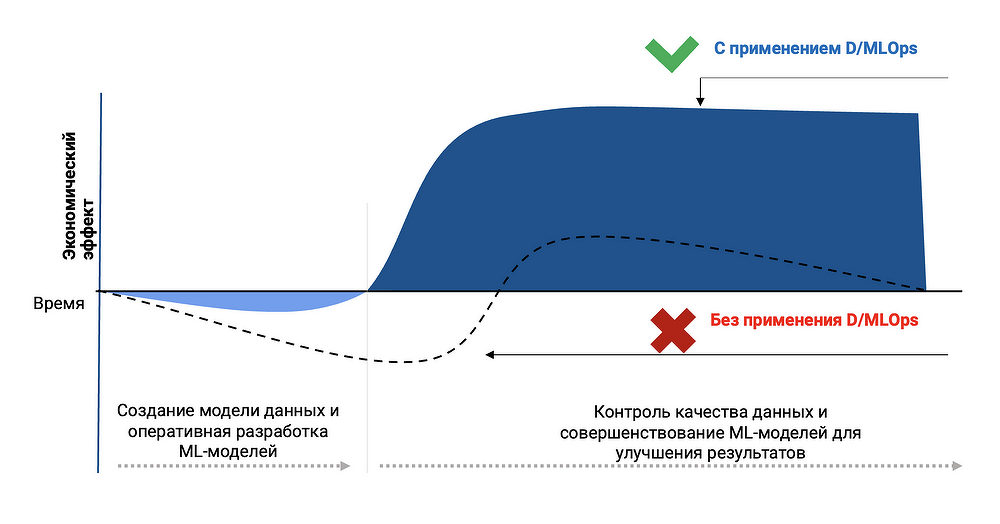
Объединенный подход мы назвали D/MLOps и построили наш продукт «Иннодата-D/MLOps» вокруг совместной реализации этих двух концепций. Помимо уже упомянутых преимуществ для бизнеса, это позволяет добиться более важной цели — сделать жизненный цикл ML-сервиса «прозрачным» и предсказуемым для спонсора и Product Owner'а. Этот подход называется Reliable ML. На начальном этапе создания ML-сервиса создается его системный дизайн, описывающий бизнес-задачу, цели и критерии успеха, используемые данные, подход к экспериментам и проверке гипотез, целевые метрики ML-моделей и, самое важное, их связь с бизнес-метриками, а также масштабирование успешных моделей и их вывод в «Прод». Наш продукт позволяет реализовать этот подход на единой платформе, контролирующей все этапы для реализации «прозрачности» ML-сервиса. В частности, некоторые модели позволяют прямую интерпретацию того, как были получены их прогнозы — например, какой вклад в % дали конкретные типы входных данных (features). Это позволяет не только контролировать работу моделей в «Прод», но и повысить доверие пользователей к их прогнозам.
Как результат, мы не просто реализуем полный мониторинг «здоровья» ML-сервиса, его входных данных, компонентов и прогнозов (это полезно как для Data Science-команды, так и для Product Owner'а), но и получаем возможность интерактивно отслеживать бизнес-эффекты от его применения (то, что хочет видеть Спонсор). Если в системном дизайне была разработана связь целевых метрик ML-моделей с их бизнес-метриками, которая была подтверждена на тестировании модели, мы реализуем аналитические дашборды по качеству запущенных ML-сервисов, их бизнес-метрикам и финансовому эффекту, которые доступны для понимания без специфических знаний в Data Science. И теперь вы всегда ответите на вопрос Спонсора, куда уходят деньги на ML.
Возможности продукта «Иннодаты» для бизнеса
Согласно нашему опыту, есть три уровня «зрелости» ML-продуктов в компании, и на каждом из них внедрение продукта «Иннодата-D/MLOps» будет иметь дополнительные бизнес-эффекты:
Вариант 1: первая модель в «Прод». Компания только начинает использовать ML-модели, и в этом случае внедрение методологий MLOps и Data Governance не дает значительного финансового эффекта на старте, при этом существенно снижает риски и сокращает время окупаемости вложений в ML, тем самым ускоряя переход к следующим уровням развития ML в компании.
Вариант 2: ускоряем Data Science-команду. У компании уже есть Data Science-команда и некоторый опыт эксплуатации ML-моделей. Это классический сценарий внедрения MLOPs, когда его необходимость уже сложно не замечать. При этом не только снижается Time-to-Market для ML-сервисов, но и устраняется Bus Factor — Спонсор становится менее зависимым от 1-2 ключевых разработчиков, ведь их знания и история достижений становятся документированными и переносимыми на всю Data Science-команду. К тому же для Спонсора появляется возможность явно определять финансовый эффект от тех или иных изменений, что в итоге приводит к росту эффективности вложений в ML-сервис.
Вариант 3: объединяем «ИТ-башни» и задаем вектор развития. В компании появились (и развились) несколько ML-направлений, в каждом из которых есть Data Science-команда. Обычно их действия при разработке ML-моделей достаточно похожи, но при эксплуатации и обновлении ML-сервисов возникают неизбежные расхождения в подходах, особенно заметные на стыке ответственности команд. В этом случае совместное внедрение инструментов Data Governance и MLOps позволяет задать единые стандарты работы для всех Data Science-команд и тем самым получить возможность реализации более сложных кросс-функциональных ML-сервисов. Хорошо описанные датасеты, пайплайны данных и модели теперь можно переиспользовать, а не писать с нуля в каждой команде. Также немаловажным становится снижение расходов на обучение новых сотрудников и ускорение их ввода в команду. Аналитические дашборды по качеству ML-сервисов и их финансовому эффекту становятся незаменимым инструментом для Спонсоров и Product Owner'ов.
Развитие продукта — федеративное обучение ML-моделей, обучение на защищенных данных
Наш продукт постоянно развивается, и мы реализуем новые решения, востребованные у наших клиентов. Например, для компаний, которые работают на конкурентном рынке, хотят использовать ML-модели, но не обладают по отдельности объемом данных, необходимым для получения качественных прогнозов, мы реализовали возможность федеративного обучения общей ML-модели на локальных данных каждой компании, без их раскрытия и передачи вне защищенного контура. В этом случае на внешний сервер, управляющий процессом обучения, передаются только коэффициенты ML-модели, и, по нашим тестам, ее качество сопоставимо с качеством прогнозов модели, обученной на объединенных данных. Впоследствии каждая компания может использовать обученную модель, и при добавлении новых участников и данных качество прогнозов только растет. Этот подход может применяться в финансовой отрасли (например, для моделей антифрода), ритейле (при прогнозировании спроса) и логистике.
Кроме того, мы пилотируем возможность обучения моделей на защищенных данных — например, когда их владелец не хочет передавать чувствительные данные внешней Data Science-команде. В этом случае используется искусственное разделение и защита исходного датасета с помощью MPC-подходов. Data Science-команда может получать результаты вычислений и обучать модели (аналогично федеративному обучению), но не может получить полный доступ к датасету и скопировать его.
Как запустить D/MLOps в своей компании
Если вы заинтересовались нашим продуктом, хотите получить больше деталей, посмотреть демо функционала и оценить проект внедрения в своей компании — оставьте заявку на нашем сайте (https://www.innodata.ru/solutions/d-mlops/).
■ Рекламаerid:Kra23vUaJРекламодатель: ООО «Иннодата»ИНН/ОГРН: 1615013510/1171690052930Сайт: https://www.innodata.ru/ Поделиться
Поделиться
