Принцип Родена в ИТ: берем базу данных и на лету отсекаем лишнее

01.02.2023
Ценность данных для коммерческих организаций и госуправления ни у кого не вызывает сомнений, а их анализ и монетизация результатов уже давно стали частью бизнес-процессов крупных компаний. BigData продолжительное время считается восходящим трендом, при этом не секрет, что значительное количество данных бизнес накапливает в структурированной форме. Их объемы могут достигать многих сотен терабайт, и вопросы оптимизации работы с ними стоят достаточно остро.

Дата: не все и не всем
Данные, накопленные компанией, обрабатывают разные подразделения, причем как внутренние, так и аутсорсные. Возникает практический вопрос, который кажется простым только на первый взгляд. Как передавать для обработки и анализа только нужный фрагмент данных, закрывая при этом все ненужное для поставленной задачи и делать это надежно? Казалось бы, проблема легко решаемая — ведь соответствующие фильтры есть в интерфейсе любой СУБД! Задал параметры, отфильтровал нужное, выгрузил в новую базу усеченные данные, полученный срез отдал аналитикам — вот и все! Однако, на практике ситуация оказывается несколько сложнее.
Объемы некоторых баз данных весьма значительны, а групп аналитиков может быть много. Получать десятки и сотни многотерабайтных срезов информации (а нужных баз может быть множество) — не самая лучшая идея с точки зрения ресурсов, ведь объемы хранилищ «не резиновые».
Сложности передачи копий баз данных
Кризис может возникнуть, когда потребуется актуализация срезов — в текущих реалиях изменения происходят очень быстро, что находит отражения в базах, а соответствующие апдейты могут оказаться значимы для анализа! Возникает необходимость отслеживать изменения, проводить R&D в поисках ответа на вопрос «а нужно ли это изменение группе аналитиков А, В, С, D…?», в зависимости от ответов выполнять «нарезку» соответствующих данных и информировать об этом команды, занимающиеся «data mining»… Заметим, что ответы на эти вопросы должны быть точны, иначе результаты тысяч человеко-часов работы высококвалифицированных специалистов окажутся, в лучшем случае, бесполезны, а в худшем — принесут серьезные убытки компании, если бизнес-решения будут приняты на основе информации, утратившей актуальность.
Кроме того, иногда нужно передавать базу разработчикам или тестировщикам, а тут нельзя просто выполнить механическое «обрезание», нужно сохранить структуру.
Более того, при передаче баз данных в другие среды необходимо сохранение консистентности данных в разных таблицах и полях (одни и те же данные должны быть одинаково представлены во всех базах).
Также не стоит забывать о самой простой и в то же время далеко не всегда решаемой проблеме — а где собственно в базе лежат данные, подлежащие масккированию — это могут быть поля с понятными названиями типа «NAME», «CARD» а могут быть и вида «S1», «S2», … «Sn» — тут требуется глубокое знание всей структуры БД. А еще могут быть записи логов, в которых тоже могут встречаться критические данные.
Таким образом процесс передачи копий баз данных требует решения следующих задач:
- Какие элементы БД должны быть перенесены в новую копию в исходном виде, какие могут быть не перенесены, какие должны быть изменены;
- Какие алгоритмы применять для каких типов переносимых данных;
- Как обеспечить констистентность копии БД и уникальность новых значений;
- Как проконтролировать корректность.
Что делать?
Ответ прост: применять автоматизированные средства маскирования Так называют программные средства модификации защищаемых данных, с помощью которых часть информации оказывается скрыта, но общая информационная структура сохранена. При маскировании защищаемые поля можно не оставлять пустыми, а их содержимое заменять на правдоподобную информацию, что важно для среды, в которую будет передаваться копия базы данных — получатели будут работать не с абстрактными наборами символов типа «пользователь 1», а с данными максимально похожими на реальные.
Для задач защиты персональных данных решение для маскирования должно выполнять генерацию ФИО, номера телефонов, идентификаторы банковских карт и другую информацию, причем не случайным набором символов, а подчиняющимся заданным правилам.
Важно, что маскирование можно применят в потоке, что позволяет никаких «нарезок» из баз не создавать, а всегда работать с актуальными данными. При необходимости, разумеется, инструменты маскирования можно применять для создания копии баз. Такие задачи тоже встречаются в практике компаний, например, для упомянутой передачи баз разработчикам/тестировщикам.
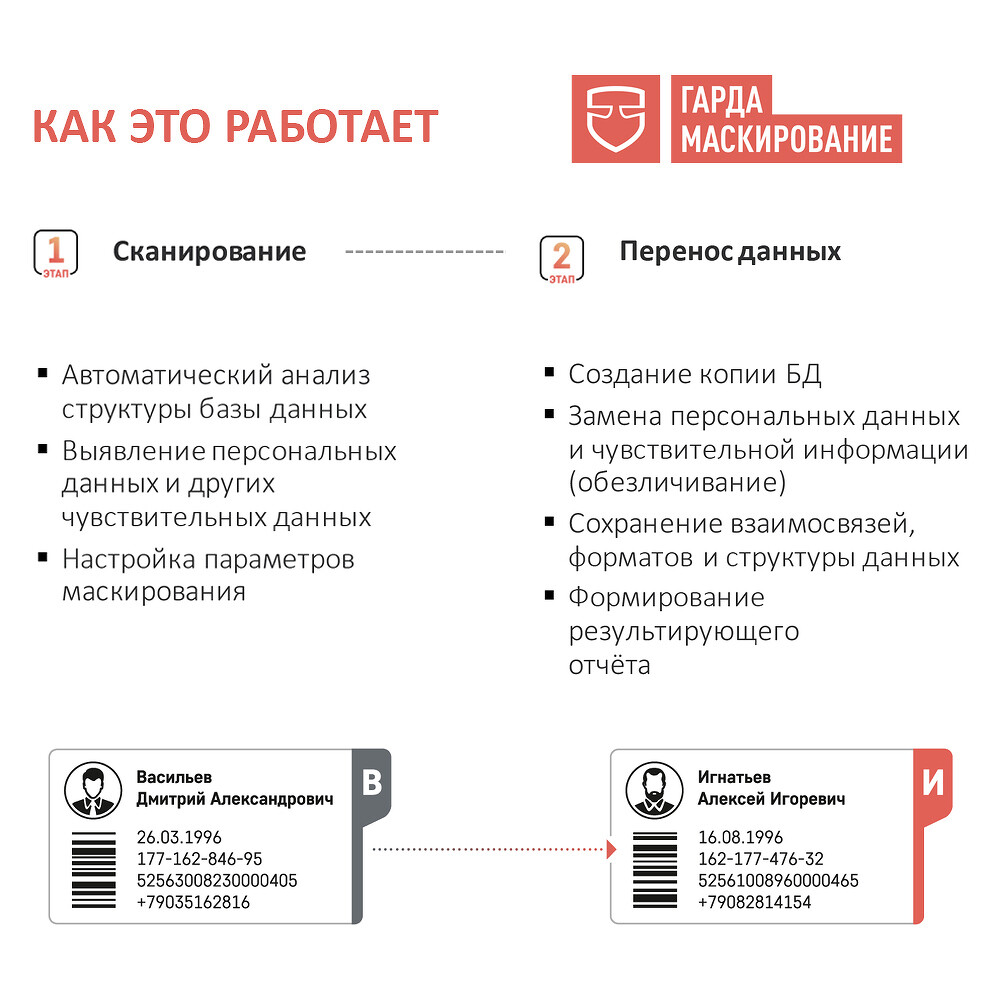
Как это работает
Сейчас наиболее востребованы системы маскирования в процессе миграции на новые ИТ-архитектуры. Например, при переезде компании с коммерческих СУБД, прекративших поддержку, на, допустим, PostgreSQL. Для подготовки разработчикам и тестировщикам нужна копия баз данных компании, но передавать исходную — нельзя по соображениям безопасности.
Мы разберем этот кейс на примере системы «Гарда Маскирование» — одного из лидеров российского рынка маскирования данных от вендора «Гарда Технологии».
На сегодняшний день система «Гарда Маскирование» применяется крупнейшими организациями для защиты информации при передаче разработчикам, тестировщикам, аналитикам и другим лицам, для которых доступ к полному содержимому баз необязателен. Решение позволяет создавать обезличенные копии баз данных, которые можно передавать третьим лицам без рисков утечек и нарушений требований регуляторов.
При создании тестовой копии базы «Гарда Маскирование» позволяет настроить правила копирования доли информации так, что не подлежащие разглашению данные будут изменены на похожие, но не соответствующие действительности. Например, при копировании заменить все телефонные номера клиентов на набор цифр, по структуре схожий с телефонными номерами. Целостность базы данных сохранена, а копию с маскированием можно безопасно передать даже разработчикам на аутсорсинге.
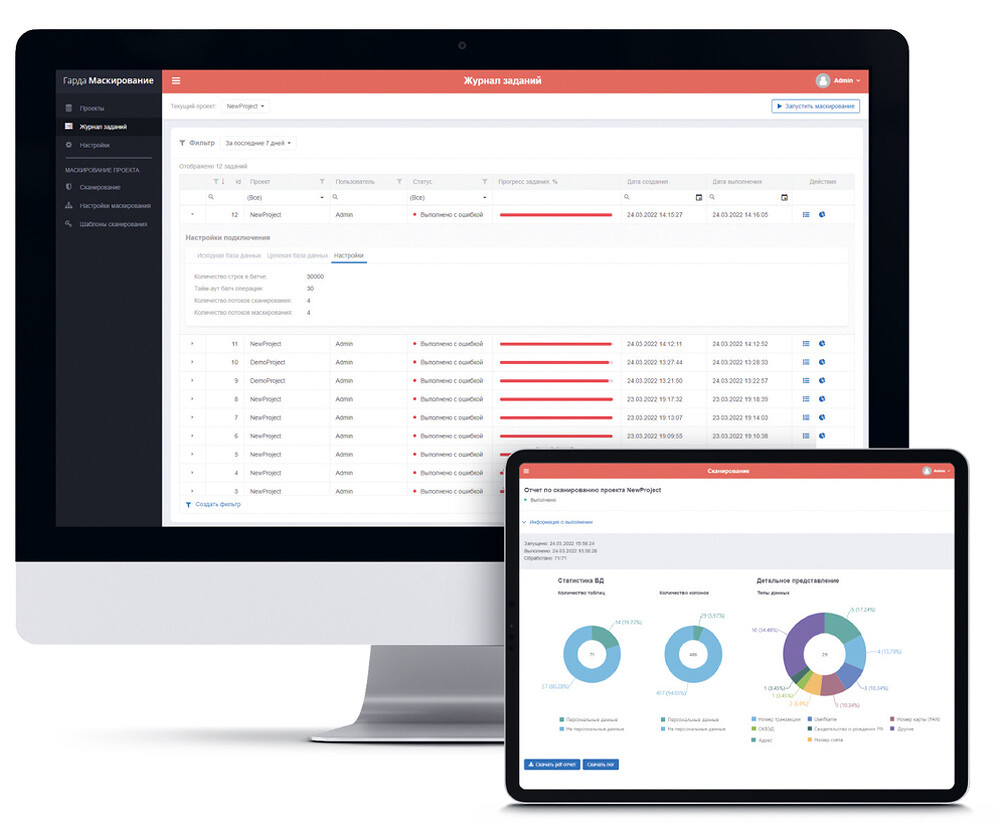
Суть технологии работы «Гарда Маскирование» состоит в двух этапах обработки данных. На первом происходит анализ структуры базы и выявление данных, подлежащих маскированию — персональных данных и других чувствительных. На втором этапе полученную маску можно применять для предоставления доступа к обезличенной базе или для создания ее копии для передачи вовне. В процессе обезличивания сохраняются взаимосвязи, форматы и структуры данных. Между первым и вторым этапом «Гарда Маскирование» позволяет предварительно проверить в реальном времени результаты работы маскирования, что позволяет до запуска процесса переноса данных избежать множества проблем с некорректным использованием алгоритмов маскирования для разных типов данных.
Также немаловажным является возможность сохранения проекта создания замаскированной копии базы данных, что позволяет автоматизировать процесс, единожды настроив правила маскирования для необходимого набора баз данных.
Напомним, что к персональным данным, согласно закону, относится как фамилия-имя-отчество, так и широкий спектр другой информации: номера банковских карт, паспортные данные, даты рождения, ИНН, ОГРН, СНИЛС, номера телефонов, e-mail, логины учетных записей и т.д., а также биометрическая информация.
Вместо заключения
Современные инструменты для маскирования способны автоматически справляться с ситуациями, проблемными для скриптов-самоделок. Например, в «Гарда Маскирование» реализованы инструменты для поиска исключений, что важно для многих практических задач. Без него может возникнуть ситуация, когда, предположим, в таблицах с техническими логам встречается последовательности цифр, соответствующих формату номеров паспорта/карты/счетов/etc., но эти таблицы в рамках текущей задачи маскировать не надо.
Разумеется, применение «Гарда Маскирование» требует аккуратности от администраторов, установку далеко не всех параметров можно передавать автоматике, а созданные фильтры необходимо тестировать перед «боевым применением».
Познакомиться с системой «Гарда Маскирование» можно 28 февраля в 11.00 на вебинаре «Пять рецептов, как победить головную боль маскирования данных».