Как ИИ выявляет в речи скрытые закономерности, незаметные человеку и стандартным алгоритмам

18.05.2026

CNews: Начнем с главного: как выглядит речевая аналитика, которая приносит бизнесу измеримый эффект? Чем отличается решение лидеров рынка?
Анна Ивлева: Речевая аналитика с измеримым эффектом — это не ретроспективные отчёты о том, что произошло, а ответы на вопросы почему это произошло и что делать завтра. Она даёт понимание по конкретным KPI: снижение нагрузки на КЦ, уменьшение повторных обращений, повышение уровня удовлетворенности клиентов, повышение конверсии и пр. Зрелые решения отличаются способностью адаптации системы под различные запросы пользователей, а также, на мой взгляд, — пониманием командой вендора потребностей клиента. Поэтому мы начинаем с бизнес-целей заказчика, проверяем гипотезы и уже в рамках пилотов валидируем влияние на запрашиваемые KPI. Это позволяет сразу показать измеримый эффект в работе бизнеса. Вот почему речевая аналитика BSS уже используется в контакт-центрах самых разных сфер: банки, ритейл, телеком, медицина и т.д.
CNews: Почему решили использовать LLM — большие языковые модели — в речевой аналитике?
Анна Ивлева: Это естественное развитие рынка и этого класса систем. Большие языковые модели зарекомендовали себя во многих сферах, и речевые технологии не исключение. С помощью ИИ можно быстрее и точнее распознавать эмоции (например, клиентский негатив), выявлять отток пользователей, находить скрытые инсайты, когда даже эксперты не подозревают об их существовании, влиять на бизнес-показатели, выстраивать прогнозы.
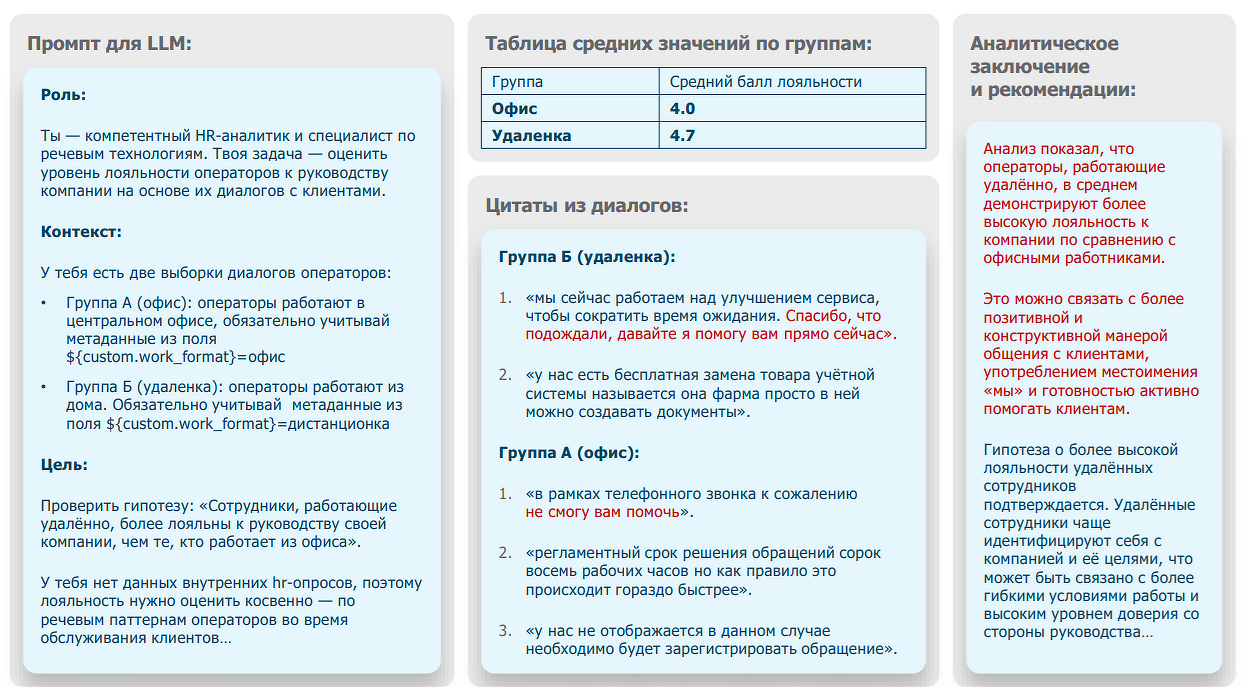
CNews: В одном из пилотов с крупным заказчиком вы проверили, какие гипотезы о работе контакт-центров подтвердит речевая аналитика. Первая звучала почти провокационно: удалённые сотрудники лояльнее офисных. Как ИИ измеряет лояльность без внутренних опросов? Приведите конкретный пример, речевой маркер.
Анна Ивлева: Да, исследование было масштабным и базировалось не только на анализе диалогов, но и на WFM-данных — информации из системы управления персоналом: например, о графике, формате и длительности работы сотрудника. Нам было важно получить инсайты об операторах в том числе, потому что для контакт-центров это не менее ценно, чем инсайты о клиентах. HR-опросы — это не панацея, ведь это тоже весьма субъективный инструмент. Не все сотрудники при заполнении подобного опроса верят в анонимизацию сбора таких данных, а кто-то попросту не готов открыто описать причины своего недовольства, и итоговая картина уже заведомо может быть искажена. При исследовании в речевой аналитике мы составили подробный промпт, сравнивая две группы операторов, работающих в офисе и удалённо, по различным речевым параметрам, таким как: реакция оператора на клиентский негатив (присоединяется ли оператор к критике процессов КЦ или же старается перевести диалог в конструктив, предлагая альтернативные пути решения вопроса); использование оператором местоимений «мы» вместо «они» (насколько оператор отождествляет себя с компанией «мы с радостью готовы помочь» или, наоборот, дистанцируется «ну руководство так решило», «такие процессы» и пр.); способ объяснения клиенту существующих ограничений (извиняется ли оператор за «такие процессы» или объясняет ограничения как объективные обстоятельства, при этом демонстрирует готовность искать альтернативы) и другие признаки. Таким образом, мы получили вывод, что удалённо работающие операторы в этой компании более лояльны к своему работодателю, и выражалось это более позитивной и конструктивной манерой общения с клиентами, более частым отождествлением себя с компанией и готовностью активно помогать клиентам.
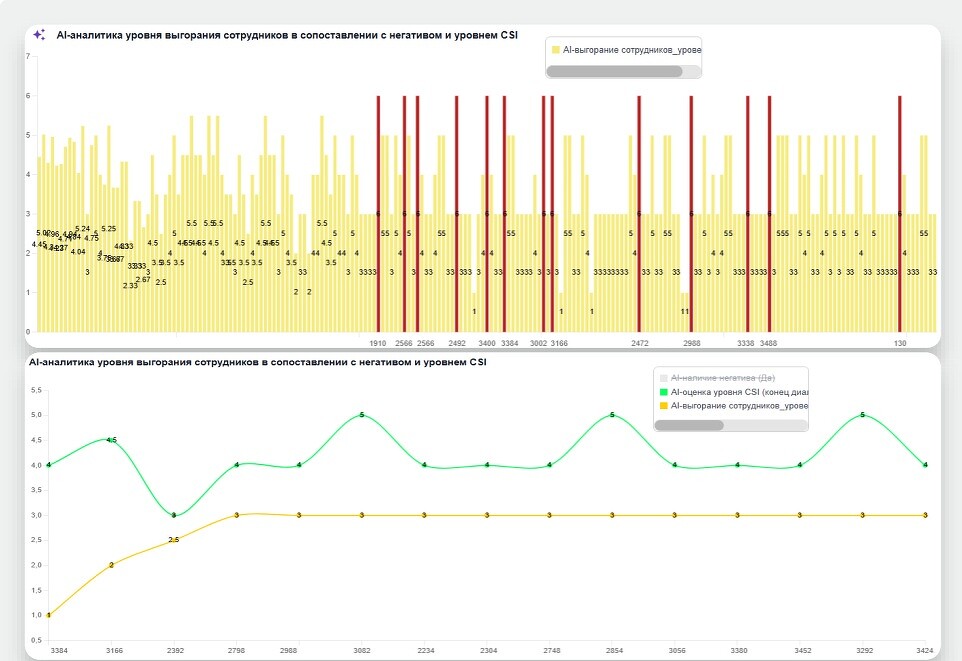
CNews: Вторая ваша гипотеза — прогноз выгорания. В вашем эксперименте модель смогла зафиксировать усталость сотрудника. Как вам это удалось определить по лексике?
Анна Ивлева: Мы измеряли уровень выгорания не только по лексическим фразам. Это не первое наше исследование в этой области, и в прошлый раз мы пришли к выводу, что недостаточно понимания о том, как именно консультирует оператор. Даже если фиксируется лексика или высокий процент тишины в диалоге, очень важно понимать, в каких условиях работает сотрудник (стаж, формат, график работы, количество опозданий в течение месяца и многое другое может быть косвенными признаками потери интереса к работе). Мы разработали детальный промпт, в котором ИИ проверял и то, как оператор консультирует, и его условия работы (получаемые из WFM-системы), и его текущие показатели эффективности (средний уровень тишины, средняя длительность диалогов, скорость речи и другое). И только такой анализ сразу в трёх разрезах позволил нам приблизиться к объективному результату от ИИ и выявить даже такие маркеры в некоторых консультациях, как «я всего лишь обычный оператор», которые начали звучать у одного оператора за месяц до его увольнения.
CNews: Далее — о репутационных рисках. В исследовании вы ожидали, что стиль речи собирающихся увольняться сотрудников станет более расслабленным или грубым, но модель этого не подтвердила. Ваше мнение, почему?
Анна Ивлева: Мы не ожидали, что стиль речи у увольняющихся сотрудников будет расслабленным; мы знаем по собственному экспертному опыту работы в контакт-центрах, что такие ситуации возможны. Наша цель была установить, может ли ИИ в речевой аналитике «поймать» такие ситуации в принципе, можно ли использовать этот инструмент для контроля таких событий. В данном исследовании у заказчика, к счастью, не оказалось таких операторов, которые бы начали грубить клиентам в конце своей работы перед увольнением, что, кстати, лишний раз косвенно подтверждает, что даже уволившиеся операторы были лояльны к этому работодателю. Но ситуация, когда оператор, зная, что это его последние дни в компании, позволяет себе условно «расслабиться», находясь на линии, очень даже вероятна в контакт-центре, а в мире, где уровень клиентского сервиса является одной из важнейших метрик, для любой организации, любого бренда вероятный репутационный ущерб может оказаться очень высок. А зачем его допускать, когда современные технологии вполне могут отслеживать и даже помогать с предотвращением таких ситуаций?

CNews: Вы прогнозируете рост уровня CSI (индекс удовлетворённости клиентов) у заказчика при условии мониторинга работы опытных операторов и масштабировании найденных лучших практик. Расскажите подробнее об этом эксперименте.
Анна Ивлева: Думаю, все хорошо представляют, что опытные операторы по сравнению с новыми сотрудниками более уверены в себе, у них есть свои собственные наработки, что и как говорить, они интуитивно чувствуют с первых фраз клиента, в каком он настроении. Но что если, сравнивая опытных операторов, давно работающих в компании, у них тоже есть чему поучиться друг у друга? Именно это мы и проверили, и эта гипотеза отлично себя показала при исследовании. Мы сравнили двух операторов, которые работают уже более четырёх лет в контакт-центре. И выявили, что у оператора «Б» присутствовали в речи яркие фразы-крючки, которые хорошо влияли на клиентов и даже успокаивали негативно настроенных пользователей. К примеру, это были фразы вроде «чтобы разрешить все ваши сомнения», «решу ваш вопрос в самое ближайшее время» и так далее. И сам тон этого оператора был очень вовлечённый, сотрудник в разговорах демонстрировал искреннее желание помочь клиенту, и клиенты это ощущали. Оператор «А» тоже грамотно консультировал, но его тон и лексика были более формальными, даже несколько отстранёнными, и было очевидно, что этот оператор старается не отклоняться от заданных алгоритмов. При детальном разборе диалогов стало очевидно, что формулировки, которые использовал оператор «Б», вполне можно масштабировать на всех операторов, включить их в скрипт при работе с эмоциональными клиентами для снижения градуса негатива. А снижение уровня негатива в свою очередь прямо влияет на показатель удовлетворенности клиентов (CSI/CSAT).
CNews: Пятая гипотеза — прогноз повторных обращений. Вы попросили ИИ оценить вероятность от 1 до 5, опираясь только на диалог. Насколько эта оценка совпала с реальными повторными звонками? Были случаи, где модель ошиблась?
Анна Ивлева: Нам было интересно сравнить, насколько высока вероятность ошибки модели, когда в диалогах отсутствует признак первичного или повторного звонка (обычно такой атрибут считается на уровне системы телефонии), и ИИ может опираться только на лексику. На наш взгляд, модель справилась довольно неплохо, но, разумеется, были диалоги, где для человеческого эксперта было неочевидно, почему большая языковая модель (LLM) поставила высокий прогноз вероятности повторного обращения клиента, тогда как из диалога такого впечатления совсем не сложилось. Однако если дополнить промпт атрибутом признака повторного диалога, это повысит качество прогноза.

CNews: В вашем исследовании фигурирует термин «каскадный промптинг». Расшифруйте для читателя: как это работает и почему без него нельзя было получить качественные ответы от большой языковой модели (LLM)?
Анна Ивлева: Всё зависит от задачи. Не всегда требуется применять каскадный промптинг, но для ряда задач он необходим. Каскадный промптинг в речевой аналитике позволяет строить запросы к модели и получать ответы на основе её предыдущих результатов. Таким образом можно получать многоуровневые каскады цепочек ответов от ИИ. Для каких задач это может использоваться? Для построения различных классификаторов, к примеру классификатор жалоб — такой кейс очень популярен среди наших клиентов: когда на первом уровне получается первичная причина жалобы клиента (допустим, жалоба на процессы компании или на конкретного сотрудника), вторым уровнем пользователь получает от ИИ сам драйвер жалобы (неверная консультация специалиста) и третьим уровнем можно определить, обоснована ли жалоба, насколько корректны были действия специалиста. Также каскадный промптинг незаменим для задач, когда на первом уровне требуется получить какие-то выводы или рассуждения от модели на уровне каждого диалога, а на втором — числовой показатель для дальнейшего использования в отчётности.
CNews: Вы подключили к анализу графики смен, длительность диалогов, стаж. Какой инсайт из внешних данных стал самым неожиданным?
Анна Ивлева: Для меня кейс с выгоранием был самым сильным инсайтом, когда мы получили реальные результаты с подтверждениями. Ещё в прошлом исследовании (осенью 2025 г.) мы были несколько разочарованы работой ИИ в области выводов о вероятном уровне выгорания сотрудников. И тогда мы как раз и пришли к выводу, что одних диалогов операторов недостаточно для понимания такой тонкой материи, как психоэмоциональное человеческое состояние, и текущие выводы, полученные с помощью интеграции с WFM-системой, нас очень порадовали.
CNews: Результат исследования по итогу применения большой языковой модели (LLM) — прогноз снижения текучести на 10%, увеличение срока работы сотрудника на 33%. Расскажите, какие расчёты и обоснования позволили вам сформировать такие оценки?
Анна Ивлева: Данные прогнозы были подготовлены совместно с нашим заказчиком, ориентируясь на их внутренние процессы контакт-центра в целом, предпринимаемые мероприятия со стороны отдела управления персоналом (HR-отдела), скорость внедрения новых инструментов и подготовленных рекомендаций в процессы, на наш опыт с других проектов и пр.
CNews: Вы выявили сразу несколько проблем, которые указывают на необходимость корректировки работы операторов. Может ли ИИ помочь на этапе дообучения сотрудников?
Анна Ивлева: Да, прямо в систему речевой аналитики встроен модуль «Агент-Тренер», позволяющий сотрудникам с определенными ролями работать с его инструментами. Это по сути ИИ-тренажер, и он уже активно используется нашими клиентами. Он отличается от обычных механик обучения в КЦ тем, что сотрудники могут проходить уроки и курсы, тренировать необходимые навыки без постоянного привлечения более опытных специалистов-наставников, которых требуется перераспределять на обучение с их основных задач. Разумеется, использование «Агент-Тренера» не означает, что начинающий оператор остаётся один на один с ИИ, но «Агент-Тренер» позволяет автоматизировать рутину, чтобы опытные операторы не совершали сами тренировочные звонки и не объясняли одно и то же, а могли сосредоточиться на отдельных, более сложных нюансах обучения.
CNews: И в качестве завершающего вопроса. Какой самый важный совет вы дали бы руководителю контакт-центра, который только думает внедрять большие языковые модели (LLM) для речевой аналитики, но боится сложностей и затрат?
Анна Ивлева: Отличный вопрос. Скажу следующее: ИИ — это не волшебная таблетка, которая сразу же с первого клика решит все проблемы. При принятии решения о развёртывании ИИ в речевой аналитике нужно чётко представлять, какие бизнес-задачи вы хотите решать с его помощью. Задайте вопросы: какая острая потребность прямо сейчас? Может быть, нет понимания, почему операторы увольняются? Почему по конкретной теме растёт количество повторных диалогов? И отсюда уже отталкиваться. И также следует продумать, как вы будете проверять и первоначально отлаживать результаты работы ИИ. Например, у одного нашего заказчика при внедрении ИИ для классификатора негатива в речевой аналитике первые результаты сравнивались с классическими лексическими словарями негатива (сравнивалась статистика по диалогам отдельно по словарям, отдельно по ответам большой языковой модели (LLM)). И при таком подходе вы сможете получить наилучший результат от использования ИИ.