Контентная аналитика накануне взлета
Контентную аналитику можно сравнить с металлургией: из огромного объема бесформенной руды она творит вещи с заданными свойствами. СЭД превращается из склада документов в хранилище знаний, корпоративный поиск значительно «умнеет», расширяются возможности САПР, учетных, скоринговых и многих других систем. Но насколько близко возможности современных систем контентной аналитики подошли к искусственному интеллекту?
13.11.2015
В 2014 году все издания обошла новость, что тест Тьюринга пройден. Конечно, это большое достижение, но означает ли это, что мы уже создали искусственный интеллект или хотя бы вплотную к этому приблизились? Отнюдь. Чат-бот, имитирующий 13-летнего подростка из Одессы, в течение пяти минут смог держать в заблуждении 33% судей – только и всего. Так что до эпохи мыслящих машин еще очень-очень далеко. Пока мы занимаемся созданием «усилителей интеллекта», а это только первый шаг на пути к искусственному интеллекту
IDC прогнозирует рост мирового рынка систем контентной аналитики за счет увеличения сегмента непосредственно самой контентной аналитики, а также когнитивных систем и корпоративного интеллектуального поиска. По оценкам IDC, совокупный темп годового роста мирового рынка составит 15% в течение ближайших четырех лет. Решения в области интеллектуальной обработки информации позволяют вводить документы и данные в информационные системы предприятий, анализировать информацию и извлекать важные объекты и факты, осуществлять семантический поиск информации в корпоративных информационных системах и внешних источниках.
Работа сотрудников, занятых умственным трудом (knowledge workers), тоже требует автоматизации. «Усилитель интеллекта должен представлять собой в сфере умственной деятельности точный аналог того усилителя физической силы, каким является любая управляемая человеком машина. Усилителями силы являются автомобиль, экскаватор, подъемный кран, металлообрабатывающий станок и вообще любое устройство, в котором человек «подключен» к системе управления в качестве регулятора, а не источника энергии», – так еще в 1964 году писал Станислав Лем в книге «Сумма технологии».
Похоже, что мы наконец-то приблизились к практическому созданию этого «усилителя интеллекта». Компьютер перестает быть просто большим калькулятором или пишущей машинкой – в мире растет спрос на аналитические системы, и особое место в этом ряду занимают технологии интеллектуальной обработки информации, потому что они позволяют включить в контур анализа и принятия решений огромные массивы текстов – все, что написано на обычном человеческом языке. А это не менее 80% всех корпоративных данных!
Тысячи тонн словесной руды на интеллектуальной фабрике
Немного перефразируя Маяковского, можно сказать, что аналитика — «та же добыча радия./ В грамм добыча, в годы труды./ Изводишь единого слова ради/ тысячи тонн словесной руды». Но, в отличие от полезных ископаемых, запасы которых сокращаются, объем информации только растет, так что аналитики нисколько не рискуют остаться без сырья. Наоборот, им нужно опережающими темпами повышать производительность своих систем, чтобы справиться с информационным потоком, причем стоит позаботиться не только о линейном масштабировании, а о большей глубине переработки, чтобы выдавать осмысленный и конкретный ответ на запрос пользователя.
И это логично: чем выше уровень передела исходного сырья, – в нашем случае той самой «словесной руды», – тем больше добавленная стоимость и тем значительнее ценность конечного продукта. Если продолжить эту аналогию, то распознавание текста можно назвать первым переделом, подобно выплавке чугуна из железной руды. Когда-то одно это казалось чудом – что изображение превращалось в текст, экономя многие часы работы. На втором переделе из чугуна выплавляют сталь, которая обладает гораздо большим спектром «сценариев использования». Соответственно, на основе технологии распознавания символов (OCR), появились интеллектуальные решения по вводу данных, которые значительно расширили диапазон сценариев, позволив вбрасывать данные из распознанных документов непосредственно в бизнес-процессы, что сразу их ускорило. Например, стало возможным создание общих центров обслуживания (ОЦО) для обработки финансовых, платежных, логистических и других документов – в масштабах холдинга это ведет к сокращению затрат на поддержку непрофильных бизнес-процессов.
Третьим переделом называют обработку металлов давлением с целью получения изделий различных форм и размеров. Здесь у нас появляются инструменты для анализа и понимания текстов на естественном языке, что открывает совершенно новые перспективы. Такая технология помогает человеку работать эффективно, то есть теперь можно обрабатывать больше информации в единицу времени, быстрее принимать решения, и добраться до тех участков информации, которые раньше были скрыты (например, из-за сложности и неочевидности связей).
Это означает, что происходит весьма существенное изменение, очередной сдвиг парадигмы: если раньше информационные технологии помогали автоматизировать рутинные операции, не требующие от работников больших интеллектуальных усилий, то сейчас появляется возможность значительно облегчить работу самых квалифицированных сотрудников в организации.
Технологии разных «переделов» могут и должны использоваться совместно для построения полной цепочки интеллектуальной обработки информации. Ведь выплавка стали и штамповка из нее разных изделий отнюдь не отменили потребность промышленности в чугуне. Пусть наши ИТ-системы еще далеки от тех высот, которые предсказывал Лем, однако они уже способны решать множество практических задач. Рассмотрим некоторые из них, где технологии интеллектуальной обработки информации уже сегодня позволяют получить значительную пользу.
В учетных системах – не только цифры
Даже в царстве структурированных данных, в мире ERP и других финансово-учетных систем есть место интеллектуальной обработке текстов. Если посмотреть на структуру базы данных внимательно, то мы увидим, что там довольно много текстовых полей, которые никак не обрабатываются обычными BI-инструментами.
Например, поле «назначение платежа». По сути, это произвольный текст, типа «аванс 30% по договору №13/15 от 25.10.2015 за выполнение ремонтных работ, включая НДС 18% - 4015,89». Поэтому даже если все платежные документы ходят у вас в электронном виде, полностью автоматизировать процесс не получится – бухгалтер должен просмотреть назначение платежа, проверить, есть ли такой договор, действительно ли мы ждем по нему аванс и правильно ли посчитан НДС.
Система интеллектуальной обработки информации позволяет автоматически находить и извлекать необходимые данные из неструктурированных полей платежных документов: номер договора, реальное назначение платежа, НДС и др. и передавать полученные данные в учетную систему. Решение сравнивает извлеченные значения с базой договоров и автоматически привязывает заказы к платежному документу. При этом также автоматически сравниваются значения НДС в платежном документе с НДС, указанным в договоре.
Станислав Карамушко, заместитель начальника управления архитектуры и анализа систем учета "Т плюс груп"

Насколько и как интеллектуальные решения изменяют бизнес-процессы в организациях?
Интеллектуальные системы, безусловно, способны менять подход к бизнес-процессам в организациях любого уровня: как полностью, так и в части снижения трудозатрат с целью улучшения экономических показателей по организации в целом. Для того чтобы достигать данной цели, по моему мнению, организация должна определить финансово-экономические параметры контроля своих бизнес-процессов и хорошо знать рынок существующих интеллектуальных решений в области информационных технологий для оптимального выбора решения.
В нашей компании мы используем данные решения с 2011 года, начиная с OCR\ICR при построении ОЦО и заканчивая последними решениями в области текстовой аналитики в приведенном выше примере с обработкой платежей в учетной системе. Главным показателем для нас всегда является экономический эффект от модернизации существующих бизнес-процессов, таким образом, без использования новых возможностей в области информационных технологий на текущий момент его достичь не удастся.
В чем их практическая польза?
Создание добавленной стоимости и снижение издержек в организации – главное, что удается получить при использовании интеллектуальных решений в организации. Конечно, многое зависит от специфики и направления ее деятельности, но в любом случае организации приходится обрабатывать большое количество информации (структурированной или неструктурированной), и делать она должна это в жестко ограниченных временных рамках с высоким качеством результата, чаще всего от этого зависит существование организации в современных рыночных условиях.
Как вы видите дальнейшее развитие решений в области интеллектуальной обработки информации?
Можно, конечно, фантазировать на данную тему, но, по моему мнению, любые инновации должны быть привязаны как к реально существующим, так и к потенциально возможным потребностям рынка. Второе сложнее, и вендоры без своих экспертов, без грамотного мониторинга параметров бизнес-процессов внутри компании и актуальных знаний в области управления информацией, не смогут формировать новые решения на данном направлении. Ключ к развитию интеллектуальных решений – это взаимодействие вендора и заказчика в одном информационном поле.
Технологии интеллектуальной обработки данных вышли из стадии НИР и достигли достаточной зрелости, чтобы быть успешно примененными на практике. Рост объемов данных и требование ускорения бизнес-процессов стали драйверами интереса бизнеса к этим технологиям, что обязательно выразится в росте числа специализированных решений для различных отраслей и сценариев использования.
Происходит очередной сдвиг парадигмы: если раньше информационные технологии помогали автоматизировать рутинные операции, не требующие от работников больших интеллектуальных усилий, то сейчас появляется возможность значительно облегчить работу самых квалифицированных сотрудников в организации
Сокращение рисков при выдаче кредитов
В текущей нестабильной ситуации банки ужесточают свою кредитную политику. С другой стороны, невозможно полностью закрутить все гайки – иначе кредитный конвейер остановится. Поэтому банкам необходимо научиться быстрее и точнее анализировать информацию о потенциальных заемщиках и принимать более обоснованные решения о выдаче кредитов. Причем одинаково плохи оба варианта ошибки – когда банк выдает кредит ненадежному клиенту и отказывает достойному.
Для этого сначала нужно собрать информацию о заемщике, а также о связанных с ним лицах и организациях, с целью оценки его платежеспособности. Затем следует провести проверку на соответствие однотипных данных из различных источников для выявления рисков фальсификации документов и выполнить анализ состояния объектов залога: определить их стоимость, расположение, факты обременения, ареста и пр. В процессе сбора информации придется обращаться к различным внутренним и внешним источникам: информационным системам банка, включая электронные досье клиентов, CRM и АБС, к сайтам и внешним базам данных, таким как Верховный суд, ЕГРЮЛ, ЕГРН, ФССП, суды общей юрисдикции, бюро кредитных историй. Также, много полезного могут дать социальные сети, блоги и СМИ.
Очевидно, что, выполняемая вручную, эта работа сама становится источником риска из-за неполноты и неточности данных – снова человеческий фактор! В текущую систему скоринга и оценки рисков может быть интегрирована технология интеллектуальной обработки информации, чтобы автоматизировать процесс. Система выполняет полный семантико-синтаксический анализ текста, извлекает сущности, события и связи между ними, что позволяет определить финансовый и социальный статус заемщика, уровень образования, проверить данные анкет, соответствие заявляемых доходов их источникам и оценить все негативные факторы – наличие отрицательной кредитной истории, привлечение к уголовной и административной ответственности, претензии надзорных и налоговых органов и т.д.
Проектная документация требует предельной точности
Проектирование зданий и любых других строительных объектов, включая кабельные, электро-, газо- и водораспределительные сети, дороги, мосты, тоннели и другие сооружения ведется в наши дни исключительно при помощи САПР. В ходе проекта создается трехмерная информационная модель здания (Building Information Model – BIM), связанная с базой данных, где хранится информация обо всех элементах модели. Такой подход значительно упрощает управление жизненным циклом объекта на всех фазах – проектирования, возведения, эксплуатации и ремонта. К тому же, наличие модели облегчает внесение изменений и позволяет автоматически генерировать спецификации.
Да, но проектная документация пишется инженерами на естественном языке, потому что машина пока неспособна автоматически создать описания и инструкции из модели. Значит, опять появляется пресловутый «человеческий фактор» – риск того, что параметры оборудования в документации и в модели не совпадают, а это может иметь весьма серьезные последствия, если мы, предположим, строим АЭС. Поэтому приходится проводить сверку модели с проектной документацией, чтобы устранить любые разночтения. Это долго и дорого.
К счастью, задача поддается автоматизации. Система интеллектуальной обработки информации сверяет сведения об объектах из модели в САПР и проектной документации и помогает выявить расхождения на ранних стадиях проектирования и строительства, за счет чего снижаются инженерные и финансовые риски проекта.
Новый взгляд на СЭД и корпоративный поиск
Когда интернет был маленьким – в прямом и переносном смысле, – для поиска использовались тематические каталоги. Например, с этого начинал свой путь Yahoo. То есть каждый сайт нужно было вручную привязать к одной или нескольким рубрикам, как товар в интернет-магазине. Сейчас это невозможно представить, потому что слишком много информации создается каждый день, и никакой штат редакторов не справится с ручной классификацией. Google приучил нас к прямому поиску по ключевым словам, и эта модель прекрасно работает во внешнем мире – человеку в ответ на свой запрос достаточно найти первый подходящий документ. Ну, или второй.
При переходе на уровень корпорации эта модель не подходит: пользователя не устроит найти «первый подходящий договор», разве что в качестве образца. Как правило, сотрудники ищут какой-то конкретный документ или полную выборку документов по запросу, что предъявляет более высокие требования к точности и полноте поиска, а этого можно достичь только за счет полного и точного атрибутирования. Сейчас это обеспечивается ручной классификацией потока входящих документов, которые затем ложатся в различные корпоративные системы, прежде всего в СЭД/ECM. Причем эту работу нельзя считать неквалифицированной и доверить каким-то практикантам-стажерам, потому что человек должен хорошо и быстро понимать суть документа и его отношение к бизнесу организации.
Автоматическая классификация документов в СЭД по их содержанию позволяет избавиться от ручной работы при регистрации, быстро и легко находить нужные документы и контролировать доступ к конфиденциальным данным. Система анализирует текст документа, будь это обращение гражданина, договор, приказ или что-то еще, определяет его категорию и тематику и классифицирует для последующего рассмотрения ответственным лицом в профильном подразделении. Это экономит время опытных сотрудников и сокращает количество ошибок: ведь однажды неправильно классифицированный документ потом никогда не будет найден.
Таким образом, СЭД превращается из регистрационно-учетной системы, служащей неким «складом документов» в корпоративное хранилище знаний, снабженное таксономией, отражающей специфику организации, и средствами интеллектуального поиска информации.
Тест Тьюринга пройден. Что дальше?
В 2014 году все издания обошла новость, что тест Тьюринга пройден. Конечно, это большое достижение, но означает ли это, что мы уже создали искусственный интеллект или хотя бы вплотную к этому приблизились? Отнюдь. Чат-бот, имитирующий 13-летнего подростка из Одессы, в течение пяти минут смог держать в заблуждении 33% судей – только и всего. Так что до эпохи мыслящих машин еще очень-очень далеко. Пока мы занимаемся созданием «усилителей интеллекта», а это только первый шаг на пути к искусственному интеллекту. То есть, IA и AI, Intelligence Amplification и Artificial Intelligence – это две большие разницы, как говорят в Одессе.
Тем не менее, уже сегодня можно сказать, что технологии интеллектуальной обработки данных вышли из стадии НИР и достигли достаточной зрелости, чтобы быть успешно примененными на практике. Рост объемов данных и требование ускорения бизнес-процессов стали драйверами интереса бизнеса к этим технологиям, что обязательно выразится в росте числа специализированных решений для различных отраслей и сценариев использования.
Как работает анализ. Пример Compreno
Уникальная технология понимания и анализа текстов на естественном языке ABBYY Compreno в отличие от многих систем, основанных на статистике и правилах, выполняет полный семантико-синтаксический анализ текста, создает его универсальное представление, извлекает сущности, события и связи между ними. Это дает возможность классифицировать информацию в зависимости от потребностей компании, выявить в текстах объекты, факты и связи между ними, чтобы дальше использовать их в традиционных BI-системах.
Этапы работы ABBYY Compreno
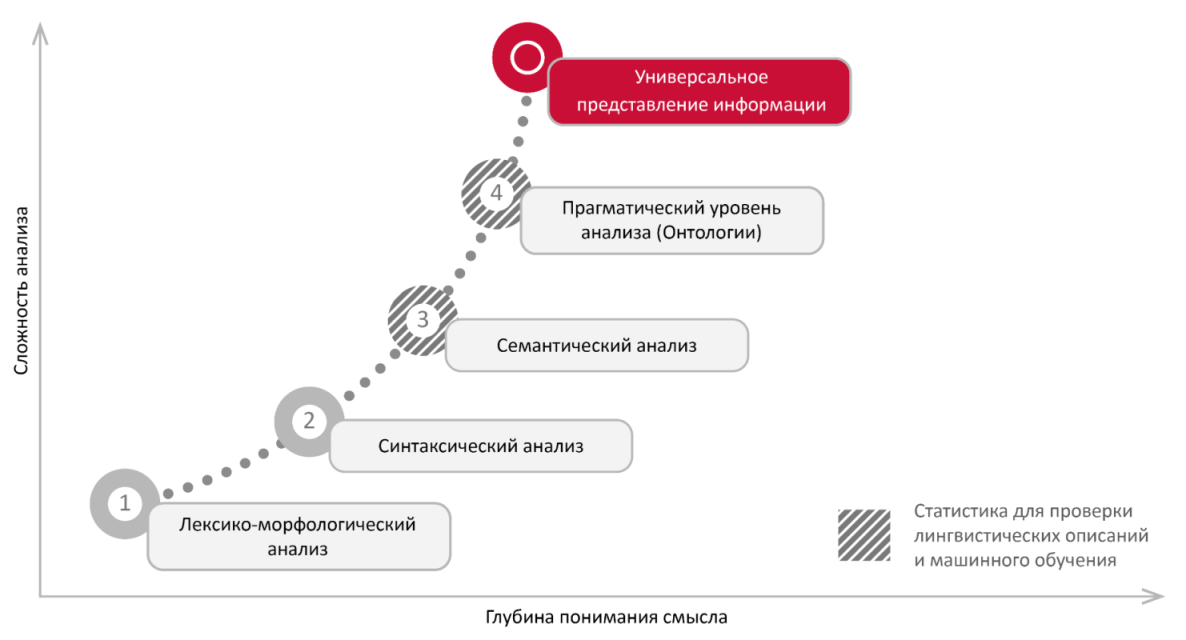
Источник: Abbyy, 2015
Массив документов сам по себе мало что дает непосредственно для анализа. Неструктурированные данные должны быть неким образом трансформированы в структурированные.
Создание структурированных данных из неструктурированных для анализа
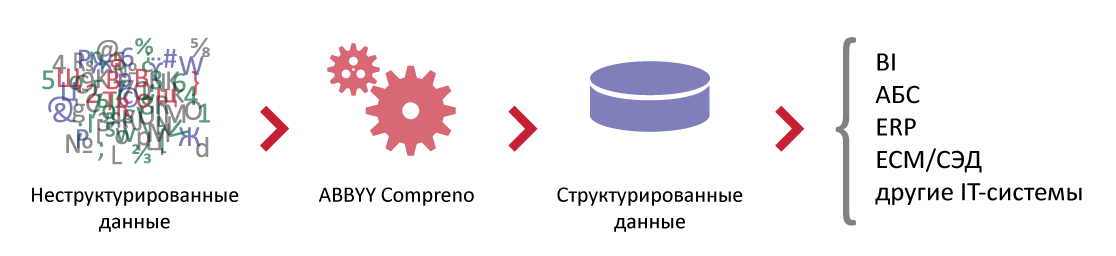
Источник: Abbyy, 2015
Compreno извлекает из неструктурированных данных сущности и факты, определяет их тематику и бизнес-контекст. Это позволяет правильно классифицировать и атрибутировать документы, чтобы затем использовать их в работе различных ИТ-систем.